Agentic Solutions / Evaluating LLM performance
Confidently scale LLM in production
For businesses integrating generative AI, evaluating performance is key. Regularly assessing how well these models meet user needs and business objectives ensures that the AI continues to add value and drive innovation without regressions.
How we can help
The lack of evaluations has been a key challenge for deploying AI models to production. By treating model evaluations as unit tests for LLM and pairing prompting with evaluations, our experts can transform ambiguous dialogues into quantifiable experiments, making AI a more manageable software product.
Create human-graded evaluation suites
Our team develops comprehensive human-graded evaluation suites to assess the performance of your LLM in various scenarios, including bad output formatting, inaccurate responses/actions, going off the rails, bad tone and hallucinations, ensuring that it meets user needs and business objectives effectively.
Create model-graded evaluation suites
We also design model-graded evaluation suites, enabling you to automatically evaluate and monitor your LLM's performance at scale. By reducing human involvement in parts of the evaluation process that can be handled by LLMs, human testers can be more focused on addressing some of the complex edge cases that are needed for refining the evaluation methods.
Govern and upgrade models
To maintain high-quality performance and prevent regressions, we provide ongoing model governance and upgrades. Our team continuously refines evaluation suites, updates models with new data, and implements improvements based on evaluation results, ensuring your LLM remains a valuable asset that drives innovation.
Companies we've helped
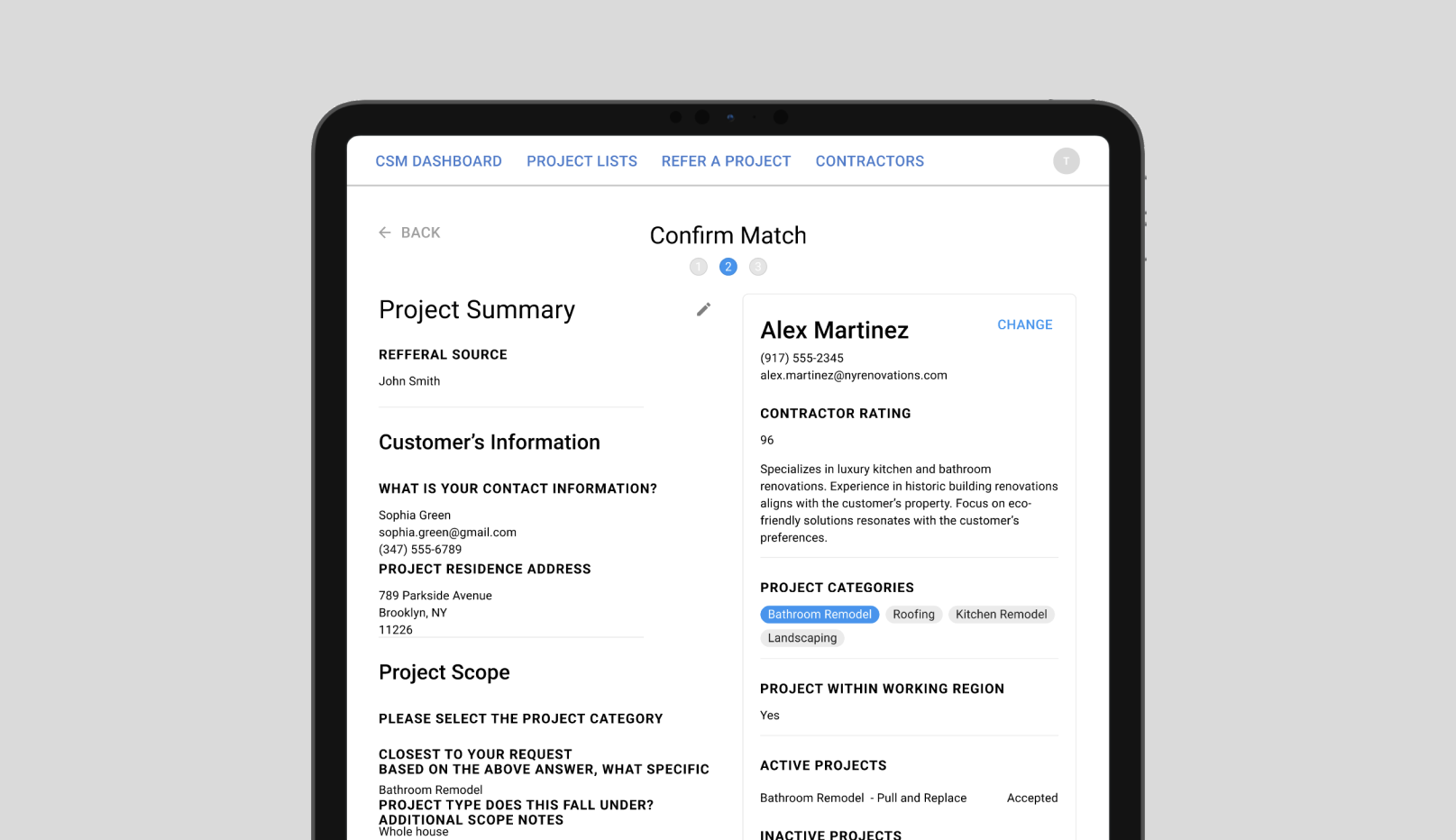
Three weeks to launch a scalable AI-powered marketplace solution with secure governance
In just three weeks, we built and deployed a secure human-in-the-loop matchmaking system for a service marketplace platform. Using generative AI and an open-source AI governance platform, the solution minimizes operational costs, accelerates lead response times, and scales without increasing headcount, with oversight, traceability, and control at its core.
Case Study

Babbly
An AI-enabled demo from concept to functional model in just 2 weeks
Babbly's founder needed a machine learning algorithm in a few weeks to close a pre-seed investment round.
Case Study

Blue J Legal
Simplifying the work of tax professionals with a mobile app
Blue J Legal successfully launched its AI-powered research tool and acquired its first paying customers during their partnership with Rangle.
Case Study

Featured Posts



Navigating the AI Roadmap: Strategies for Efficient Integration
In this webinar, we talk about useful frameworks for companies thinking about deploying AI in their context and building products with it.
Ship AI Features


Unlock smarter e-commerce merchandising with AI and multimodal language models
A practical guide to using AI to curate product collections at scale, make product recommendation and search algorithms smarter with semantic awareness, and empower teams to deliver seamless customer experiences.
Ship AI Features
A practical guide to AI-driven website internationalization
Generate nuanced translations for your e-commerce site using AI. Learn how to set up, fine-tune, and integrate AI models seamlessly with your headless CMS for automatic content translation. Uncover practical steps for implementation, from choosing the right language model to architecting efficient translation workflows that align with your budget and goals.
Ship AI FeaturesShip AI that holds up in production
Get an AI feature live without guessing
We pair UX, engineering, and governance to design LLM features users trust, ship guardrails that hold, and measure what's actually working. Start with a scoped discovery and a concrete plan.
Talk to an AI leadFrom the blog

How to Improve AI ROI and Stop Your Budget From Spiraling
73% of enterprises exceeded their AI cost projections this year. The fix isn't rationing tokens. It's changing what you use them for.
Agentic AI


What is an Agentic CMS?
Your CMS shouldn't require a vendor's permission to evolve.
Escape CMS & Commerce Lock-In
The Fast Fashion Era of SaaS: How Agentic Development Disrupted Our Business Model
For over 12 years, our business model has been straightforward: time and materials billing based on developer hours. While others competed on price with offshore teams, we competed on our ability to solve complex problems in highly regulated industries, hitting impossible deadlines time and time again. We became the team enterprises called when they couldn't afford to fail – or when they'd already tried and it didn't work.
Ship AI Features