

What's the fastest path to add AI to my existing tech stack?
A simple use case I could build quickly was a headless AI agent that leverages content from our website to generate LinkedIn posts. I wanted the posts to align with our published perspectives and insights and brand voice.
Within one day, I created the application, and my team was using it the next day.
To make this work, I needed a flexible, cost-effective solution that easy to implement and deploy. Here's a high-level overview of where I landed:

Step 1: Using a headless CMS to ground the LLM
Since we were already using a headless CMS, I could easily provide structured website content to an LLM. This meant the AI could reference our blogs and website pages to generate informed, on-brand posts about our perspectives and experiences. By implementing RAG, I could ensure that the AI's responses were contextually accurate and grounded in our existing content.
Step 2: Setting up and deploying the application
I started with Vercel's OpenAI + AI SDK Chatbot template, which generated a React + Next.js application with:
- The Vercel AI SDK (compatible with OpenAI, Anthropic, Google, and many other LLM providers),
- Pre-styled components using shadcn/ui and Tailwind CSS, and
- Deployment to Vercel's front-end cloud infrastructure.
With v0, it took less than five minutes to generate front-end components and deploy the application.

Step 3: Choosing the right LLM
I initially used OpenAI's GPT-4o mini because I already had OpenAI API keys, and it was loaded by default in the v0 template I used. Later, I switched to Google's Gemini 1.5 Flash-8B because I got free API credits through Google's AI Studio. Performance was comparable between GPT-4o mini and Gemini 1.5 Flash-8B.
| Model | Input | Output | Context Window | Output Limit |
|---|---|---|---|---|
| Gemini 1.5 Flash-8B | $0.08 | $0.30 | 1 M | 8 k |
| GPT-4o mini | $0.15 | $0.60 | 128 k | 16 k |
| Gemini 1.5 Flash | $0.15 | $0.60 | 1 M | 8 k |
| Claude 3.5 Haiku | $0.80 | $4.00 | 200 k | 8 k |
| GPT-4o | $2.50 | $10.00 | 128 k | 16 k |
| Gemini 1.5 Pro | $2.50 | $10.00 | 2 M | 8 k |
| o3-mini | $1.10 | $4.40 | 200 k | 100 k |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 200 k | 8 k |
| o1 | $15.00 | $60.00 | 200 k | 100 k |
| Claude 3 Opus | $15.00 | $75.00 | 200 k | 4 k |
Step 4: Implementing RAG with Sanity's embeddings API
To make the AI agent context-aware, I used Sanity's embeddings API to generate a vector index of our website content directly in my browser without writing code or manipulating data. The API also handles querying and retrieving relevant documents from the CMS.
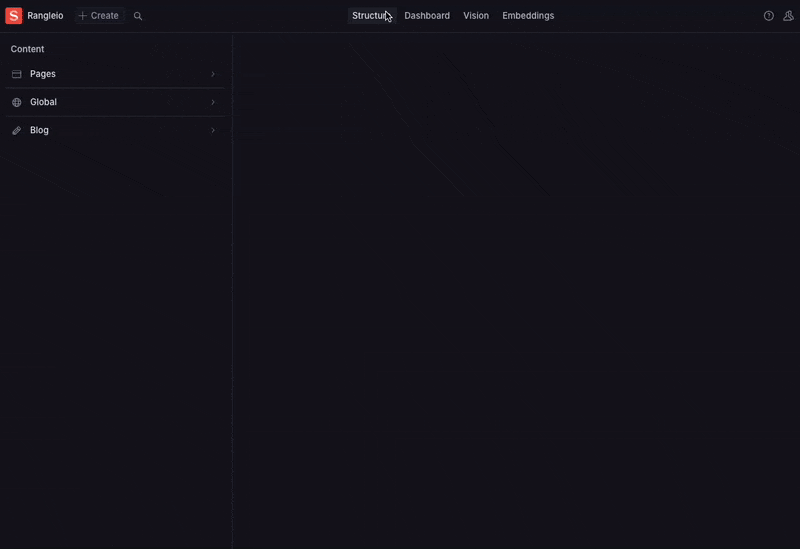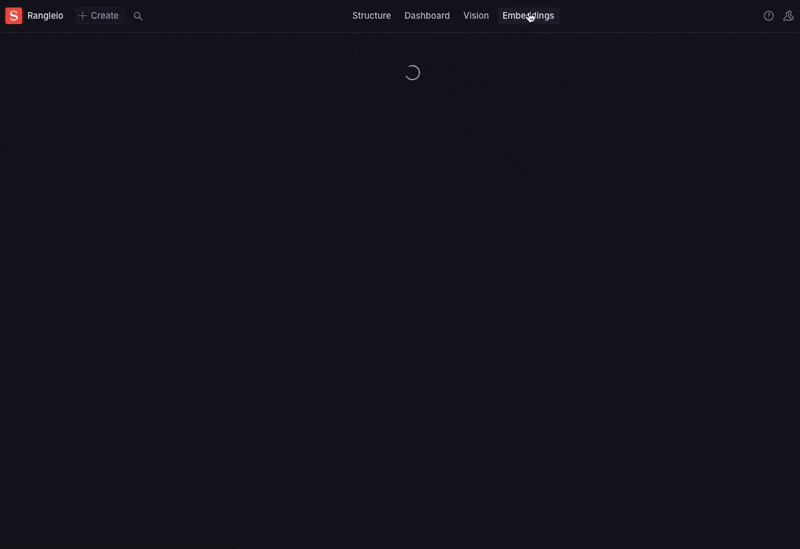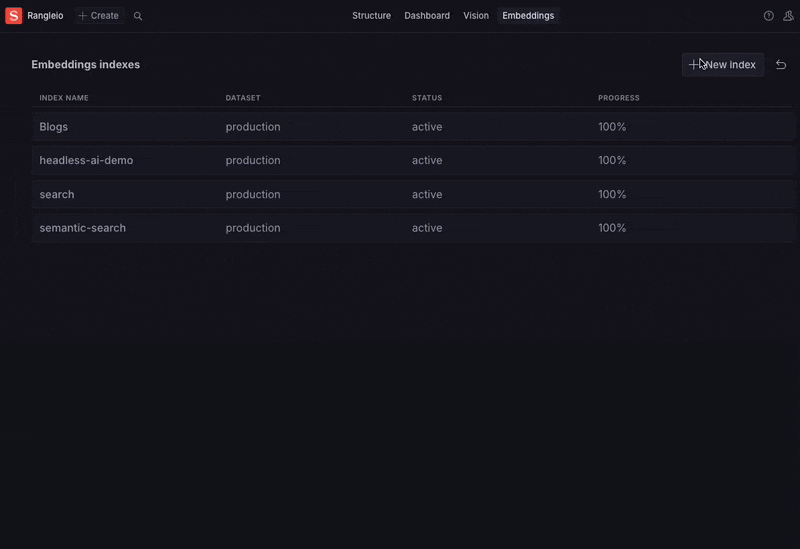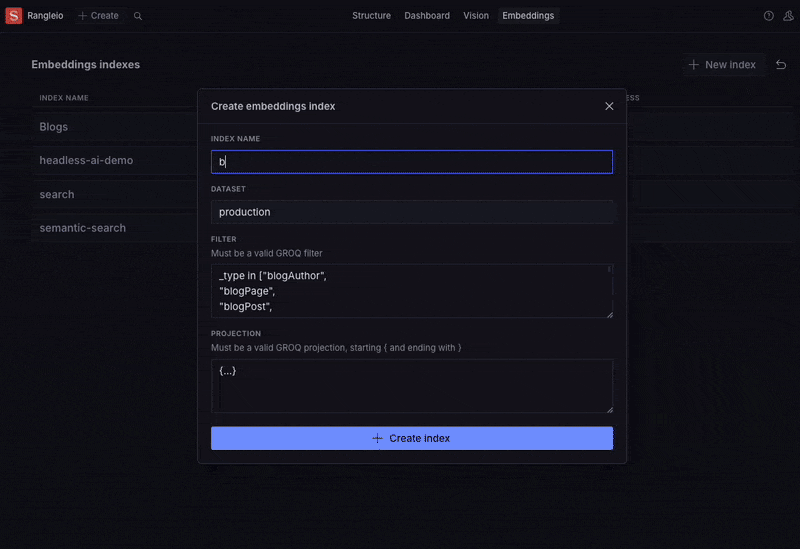
(If you're missing the "Embeddings" tab, you'll likely need to enable embeddings in your Sanity Desk setup.)
I also added a feature that temporarily stores past messages in the browser, allowing users to ask for revisions without losing context or retrieve additional context. The chat resets only when the page is refreshed.
Step 5: Implementing open-source AI governance
Before I could share my experimental application with my colleagues, I needed to be able to monitor how it was being used and how the model was responding, so I could assess and improve its performance and utility. And before I could share it with the general public, I needed a way to monitor usage and performance more broadly, including cost management.
Airbender is an open-source governance tool developed by my colleagues at Rangle. It logs every interaction between AI systems and users. I can see who's using my application, what they're asking it, and how it responded. If the agent begins generating off-brand or inappropriate recommendations, Airbender's logs can pinpoint when and why the behaviour began. It highlights potential risks, such as model drift or unexpected behaviour changes.

Airbender also allows non-technical team members to manage AI systems without relying on developers. They can change which LLM provider or model the AI agent uses, or adjust the prompt to improve performance and support new use cases – all without touching any code.** Administrators can pause the system, inspect logs, or configure workflows** without needing to involve technical teams.
Airbender provides real-time dashboards for monitoring system health and usage, along with tools to roll back to previous system versions for urgent issues.
Deploying AI without budget approval
My AI agent was built and deployed at no additional cost. Here's a breakdown of the tools I used:
- v0 by Vercel: Their free tier lets you generate and deploy up to 5 projects.
- Vercel: Their free Hobby plan supports up to 200 projects, with very generous usage limits.
- Google AI Studio: I used a free API key from Google's AI studio.
- Sanity's embeddings API: Available at no extra cost with their Growth plan ($15/mo).
- Airbender: Open-source and completely free to use.
Leveraging a headless architecture and open-source tools not only minimizes costs but also reduces vendor lock-in and concentration risk, and future-proofs your tech stack.
Final thoughts
Building an AI agent doesn't have to be complex or expensive. By leveraging your existing content and data infrastructure, you can build reliable AI agents where they create the most business value – without a complete overhaul of your existing tech stack.
Feel free to add me on LinkedIn, whether you have questions, want to swap ideas, or just chat about what you're building. I'd love to connect and learn from you!






