
This is a rather meaty post that will hopefully shed some light on concepts that have been misunderstood and under-utilized, in the general community. The goal of this post is to explore the concepts behind map and reduce, and to illustrate how they can simplify algorithms for dealing with arrays of data.
TL;DR
If you are a Map/Reduce pro in JavaScript, you know how they each work under the covers, and you've been using them to write highly-testable solutions to real-world problems, you're likely good to skip this article, given two caveats:
- You understand that map has nothing to do with looping, except that it is usually used as an array method.
- You may want to hop down to the bottom of each section.
Regardless, you are likely going to want to check out the real-ish world examples.
What is Map?
Well, let's look at some code. What if we had some array of numbers, and we wanted to increase each value by 1?
let numbers = [1, 2, 3, 4];
function addOneToEach(numbers) {
for (let i = 0; i < numbers.length; i += 1) {
const number = numbers[i];
numbers[i] = number + 1;
}
}There's a problem with this, though. The sort of function that mutates external references is very hard to reason with. As soon as this type of code is running in someone else's module on an array that you own, your understanding of your own code goes out the window. We learned the hard way that global variables are a terrible idea. Having variables that can change value on you, unexpectedly, because someone else's code changed them, makes it very hard to track down bugs. It's even harder to test that there aren't any. It's safe to say that the local version of the same problem (mutating local members/variables), is just as bad; perhaps worse, because with globals at least you are assuming that you're working with something that might backfire.
Typically, the way to solve that problem is to return a copy that is modified, rather than modifying the original array.
function addOneToEach(numbers) {
let newNumbers = [];
for (let i = 0; i < numbers.length; i += 1) {
const number = numbers[i];
newNumbers.push(number + 1);
}
return newNumbers;
}ES6 also brought us the ability to write terse iterations over iterable primitives.
function addOneToEach(numbers) {
let newNumbers = [];
for (let number of numbers) {
newNumbers.push(number + 1);
}
return newNumbers;
}In each of these cases, we're still writing a bunch of boilerplates.
In the case of any of the looping code, there is really only one part of the whole algorithm that actually concerns itself with the "addOne" part.
That's the number + 1 sub-expression, regardless of whether we're pushing the result, or assigning it, the only thing of business value in that algorithm is that expression.
What if we wanted a similar algorithm to double each element?
function addOneToEach(numbers) {
let newNumbers = [];
for (let number of numbers) {
newNumbers.push(number + 1);
}
return newNumbers;
}
function doubleEach(numbers) {
let newNumbers = [];
for (let number of numbers) {
newNumbers.push(number * 2);
}
return newNumbers;
}That's not a lot of code on its own, but soon enough, you're going to have a file full of loops, and very few lines which provide any real value. They say that if you write the same thing three times, you should refactor it.
How many loops have you written in your life?
What would we refactor it into?
What if we could make a higher-order function that did our looping for us, and let us run just the custom part of the code that we care about?
function loopOverAndTransformEach(transform, array) {
const newArray = [];
for (let el of array) {
newArray.push(transform(el));
}
return newArray;
}We don't have to write another loop ever again, for the sake of changing values in arrays. Putting this to use, we can solve a lot of problems.
const incremented = loopOverAndTransformEach((x) => x + 1, [1, 2, 3]); // [2, 3, 4]
const employees = loopOverAndTransformEach(convertPersonToEmployee, people);The code here is much more expressive. These lines are practically self-documenting.
Even better, we could return another function that expects the array in a separate function call.
const addOneToEach = loopOverAndTransformEach((x) => x + 1);
addOneToEach([1, 2, 3]); // [2, 3, 4]
addOneToEach([2, 3, 4]); // [3, 4, 5]
const convertPeopleToEmployees = loopOverAndTransformEach(
convertPersonToEmployee,
);
convertPeopleToEmployees(somePeople); // someEmployees
convertPeopleToEmployees(otherPeople); // otherEmployeesGreat news; you have been using map this whole time!
We call it map because it's about one value mapping to another.
Mapping is Not About Loops
Have you seen the detective shows where some encoded message is using the most simple cypher ever?

Each number maps onto its corresponding letter. In our world, the function defines the steps to get from the value in the A column to the value in the B column.
const convertPeopleToEmployees = map(convertPersonToEmployee);
convertPeopleToEmployees(specificPeople); // specificEmployeesAn important consideration here is that in JS we almost always talk about map in the context of arrays.
But it's not really a way of dealing with arrays. It's about mapping one value into a new value, and getting the same type back.
So with ES6' arrow function, we can call [1, 2, 3].map(x => x + 1); (the map method has been around since ES5) and we get a new array back.
In certain Promise libraries, they give you a map method. It gives you a new Promise, with the value transformed. In Observable libraries, map gives you a new Observable, with its values transformed.
So the takeaway is that you don't have to care if map loops or not, or how it loops, or in some languages how many threads it uses. If you are using a map method on an array, or on a library Promise or Observable, or anything else, it will do what it has to do to transform the value(s), and give you back the same type, so that you can keep calling map on the result.
Our function isn't good enough to deal with many other mappable types (because it manually loops), but that's as easy as having the function default to calling map on whatever it's passed.
function map(transform, mappable) {
return mappable.map(transform);
}Problem solved. We can pass anything that has a similar map method through, and it will just work. You could have your own object with its own map behaviour, and it would be compatible.
In fact, we can create our own Mappable objects. We'll just make a constructor that takes a value, and returns an object with its own map method.
Remember that what gets returned from the map needs to be a new Mappable object (so that you can keep chaining calls to map).
function Mappable(x) {
return {
value: x,
// return a new mappable, filled with f(x)
map: (transform) => Mappable(transform(x)),
};
}
Mappable(10)
.map((x) => x * 2) // Mappable(20)
.map((y) => y + 1) // Mappable(21)
.map((z) => z / 3) // Mappable(7)
.value; // 7
const mappable1 = Mappable("hi");
const mappable2 = map((str) => str.toUpperCase(), mappable1);
mappable2.value; // "HI"
const person = Mappable(personData);
convertPeopleToEmployees(person); // Mappable(employee)What About Reduce?
We've covered a lot of ground with map.
A lot of the same thinking applies to reduce.
What reduce actually represents is a means of summarizing data as a single value.
const numbers = [1, 2, 3, 4];
const initialValue = 0;
const getSum = (total, number) => total + number;
const sum = numbers.reduce(getSum, initialValue);In this example, our code only cares about the final value, and the steps that we take on an element to get there.
In this function, we have a total and a number. We also have an initialValue which sets the value of total for the first run of the function.total is an aggregation. Whatever we return from our summarizing function becomes the new aggregated value. When we run out of elements to aggregate, the final value becomes the returned result of the reduce.
If we were to map the actions of the example into a table, where each row was running the function on the next element in the array, we would end up with the following:
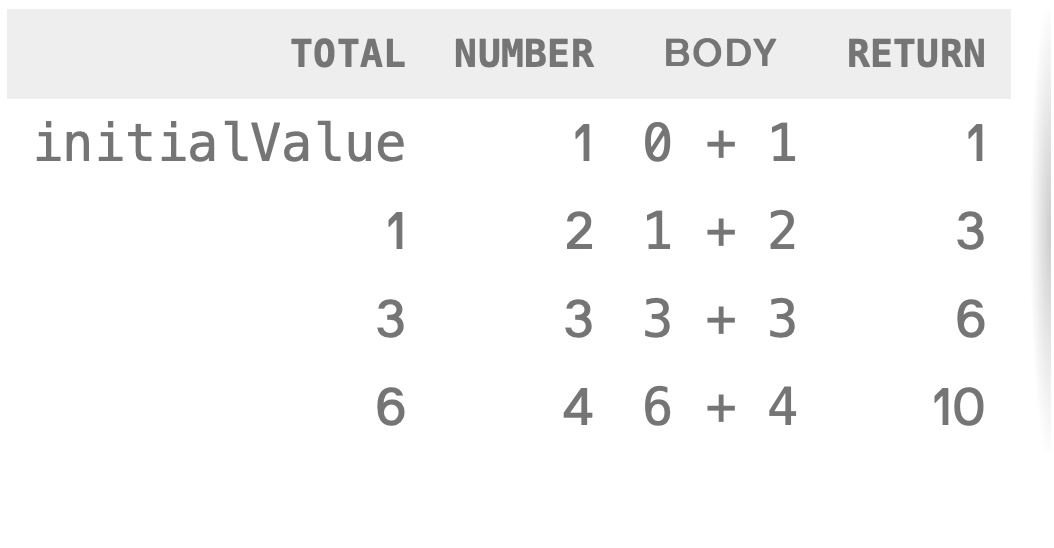
console.log(sum); // 10The type of the final value does not need to match the type of the element. In this case, the type of total and the type of each number are Number. That is not always the case.
It's okay if that seems unintuitive; we'll get into more examples momentarily.
Inside of a reduce, you are given the current value of the accumulator, and the next element to be included in the summary. Whatever you return becomes the new value of the accumulator.
function reduce(summarize, initialValue, array) {
let result = initialValue;
for (let el of array) {
result = summarize(result, el);
}
return result;
}Let's break from the theory for a second, and look at some practical (if simplistic) problems which can be spotted in the wild.
Provide the sum of the elements in an array:
const numbers = [1, 2, 3, 4];
// imperative example
let sum = 0;
for (let i = 0; i < numbers.length; i += 1) {
const x = numbers[i];
sum += x;
}
// functional example
const add = (accumulator, x) => accumulator + x;
const sum = numbers.reduce(add, 0);
// terse example
const sum = numbers.reduce((x, y) => x + y, 0);Note that once you know what reduce does, even the terse version can be very simple to understand.
Combine chunks of text into one string:
const strings = ["a", "b", "c"];
// imperative example
let str = "";
for (let i = 0; i < strings.length; i += 1) {
const chunk = strings[i];
str += chunk;
}
// functional example
const combine = (accumulator, x) => accumulator + x;
const str = strings.reduce(combine, "");
// terse example
const str = strings.reduce((x, y) => x + y, "");Remove duplicate values:
const duplicates = [1, 2, 3, 2, 3, 6, 4, 5];
// imperative
let uniques = [];
for (let i = 0; i < duplicates.length; i += 1) {
let value = duplicates[i];
let found = false;
for (let j = 0; j < uniques.length; j += 1) {
let test = uniques[j];
if (value === test) {
found = true;
break;
}
}
if (!found) {
uniques.push(value);
}
}
// human-friendly imperative
let uniques = [];
for (let i = 0; i < duplicates.length; i += 1) {
let value = duplicates[i];
let found = uniques.indexOf(value) >= 0;
if (!found) {
uniques.push(value);
}
}
// functional
const includes = (value, array) => array.indexOf(value) >= 0;
const includeFirstOccurrence = (array, value) => {
const found = includes(value, array);
return found ? array : array.concat(value);
};
const uniques = duplicates.reduce(includeFirstOccurrence, []);
// terse
const includes = (value, array) => array.indexOf(value) >= 0;
const uniques = duplicates.reduce(
(array, value) => (includes(value, array) ? array : array.concat(value)),
[],
);It's key to note, here, that the type of each element is a Number, while the value of the accumulator is an Array. This is a clear example of the aggregator and the elements being of different types.
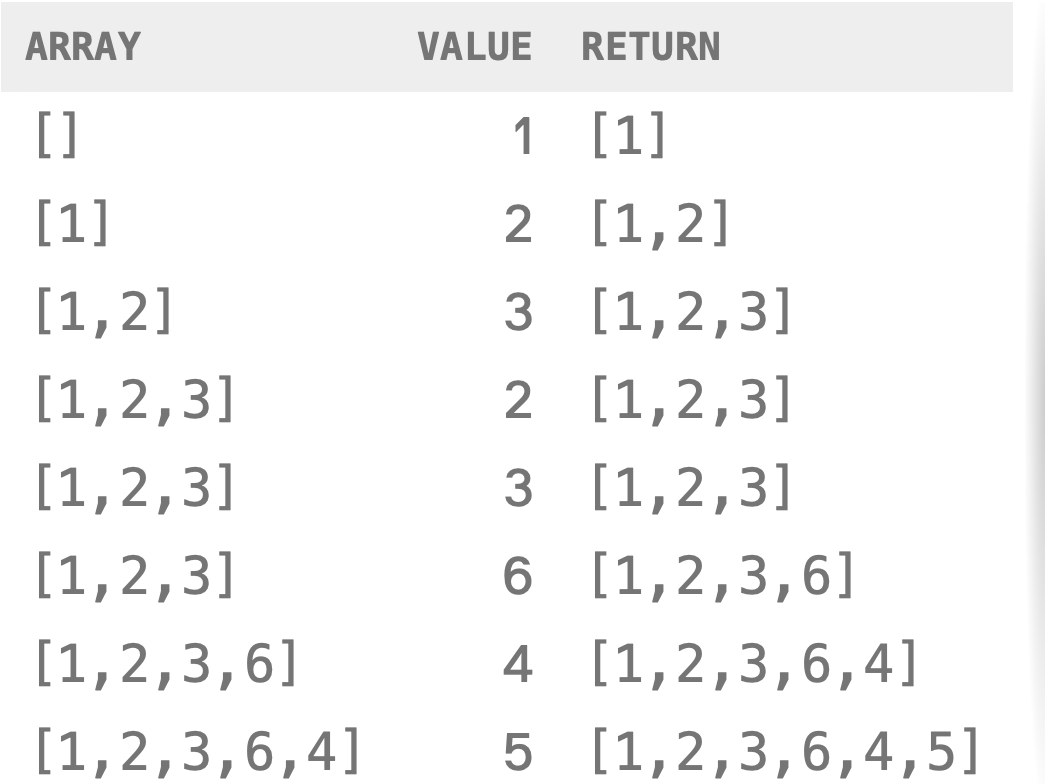
Flatten the contents of a 2D group of arrays:
As a preface to this problem, we often find ourselves with an array of stuff to deal with. Sometimes, we find ourselves with two or more arrays of the same type of stuff, and what we really need is one array that combines it all. We usually get there via array concatenation, and this is true in just about any language. In more traditional cases we might say something like:
List<Item> items = new ArrayList<Item>();
items.addAll(itemsOne);
items.addAll(itemsTwo);
// ...
items.addAll(items_N);We typically did this line by line. If the list of arrays that you need to join just keeps growing, why not make it a list, itself, that you can loop through and join them all with fewer lines of code? If that sounds confusing, don't worry; we're going to start with a simplified version for now, and see stronger use cases for this pattern at the end.
const groups = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
];
// imperative example
let flattened = [];
for (let i = 0; i < groups.length; i += 1) {
const subgroup = groups[i];
for (let j = 0; j < subgroup.length; j += 1) {
const x = subgroup[j];
flattened.push(x);
}
}
// human-friendly imperative example
let flattened = [];
for (let i = 0; i < groups.length; i += 1) {
const subgroup = groups[i];
flattened = flattened.concat(subgroup);
}
// functional example
const concat = (array, group) => array.concat(group);
const flattened = groups.reduce(concat, []);
// terse example
const flattened = groups.reduce((a, b) => a.concat(b), []);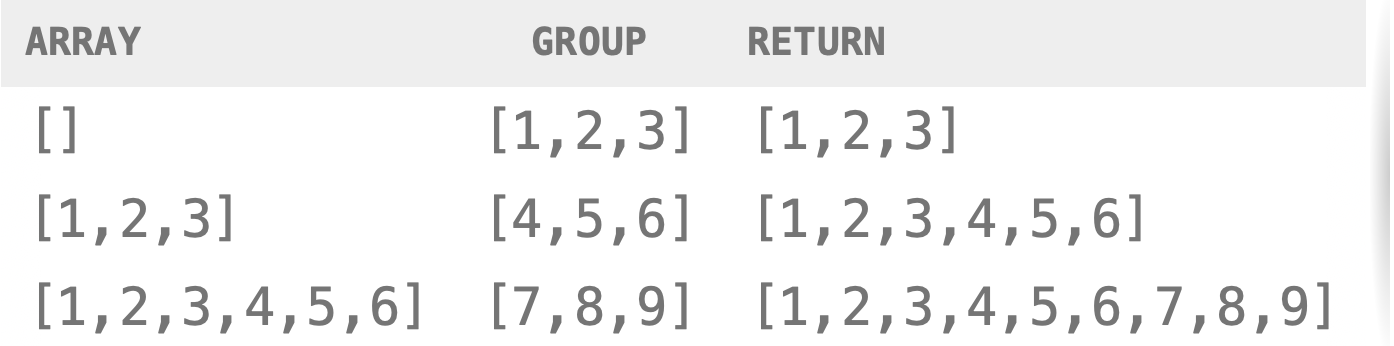
console.log(groups); // [[1,2,3],[4,5,6],[7,8,9]]
console.log(flattened); // [1,2,3,4,5,6,7,8,9]What if you wanted to take a 2D array of numbers, increment each number by one, remove duplicates, and output as a string of the remaining numbers?
const grid = [
[1, 2, 3],
[3, 4, 5],
[5, 6, 7],
[7, 8, 9],
];
const includes = (value, array) => array.indexOf(value) >= 0;
const concat = (a, b) => a.concat(b);
const keepFirstOccurrence = (arr, el) =>
includes(el, arr) ? arr : arr.concat(el);
const flattenAddOneToUniquesAndSerialize = (grid) =>
grid
// make one big array
.reduce(concat, [])
// remove duplicates
.reduce(keepFirstOccurrence, [])
// add one to each of the remaining numbers
.map((x) => x + 1)
// convert to strings
.map((x) => `${x}`)
// concat strings together
.reduce(concat, "");
const result = flattenAddOneToUniquesAndSerialize(grid);Each of the functions used in the solution is happily reusable, and very easily testable. The entire algorithm itself is equally testable, and really just six lines which are very focused on solving the problem at hand, instead of the looping and branching.
Also note that we used concat on both arrays and strings. We didn't have to, of course, but here we took advantage of polymorphic reuse of that function.
What about more complex real-world problems?
Believe it or not, that's where these techniques shine.
Problem 1: Accounting
You're the lucky developer who was picked to help generate sales reports at your company, while the finance team switches accounting software. They want three reports:
- A list of sales teams, by team name and total revenue earned
- The total revenue made by the company, regardless of team
- The name of the employee who made the most money
You know that the data looks like:
const data = [
{
// SalesTeam object
name: "AB-Team", // team.name
members: [
{
// A SalesPerson object
name: "Bob McKenzie", // team.members[0].name
sales: 1000, // team.members[0].sales - in dollars
},
// ... more sales people
],
},
// ... more sales teams
];So, how might you generate the reports?
Let's start with the easiest, which might surprisingly be the sum of all teams.
// give me the total of all sales from
// `data[i].members[j].sales`
const getTotalRevenue = (data) =>
// a list of teams; each team has a list of members
data
// a list of lists of members
.map((team) => team.members)
// a list of all members
.reduce((a, b) => a.concat(b), [])
// a list of all revenue numbers
.map((person) => person.sales)
// adding all revenue together
.reduce((total, sales) => total + sales, 0);Next, let's look at getting the person who sold the most.
If you consider what we're doing, the last report isn't all that different. Rather than the sales data out of the final list, we need to keep track of the whole person. And we probably want a way of comparing two people. Beyond that, the first part of the function should be exactly the same; we want to turn the data into a list of lists, and then flatten it.
// I'm going to use this fake person to compare
// against the first salesperson.
// this saves me from having special cases like
// null-checks in my code
const emptyPerson = { name: "Nobody", sales: -Infinity };
// give me the person with the highest sales so far
const getBestBySales = (best, person) =>
person.sales > best.sales ? person : best;
// give me the person with the highest sales of all
const getBestSalesperson = (data) =>
data
// go from a list of teams to a list of lists of people
.map((team) => team.members)
// go from a list of lists of people to a list of people
.reduce((a, b) => a.concat(b), [])
// go from a list of people to a person
.reduce(getBestBySales, emptyPerson);Did you notice the potential bug? What happens if people tie for first place? You could solve that by keeping a list of all of the top performers and replacing it with a new list, if the next salesperson beat all of the ties. Regardless, it should be really easy to spot (and fix), now that the logic is all on its own.
The last report is going to be a little different, isn't it. It's different in that we need a list of teams. We already have a list of teams. The list we need, though, has a name and a revenue, not a name and a list of members.
// give me a list of teams like `{ name: "...", revenue: ... }`
const getRevenueByTeam = (data) =>
// make new objects with "name" and "revenue" properties
data.map((team) => ({
name: team.name,
revenue: team.members
// list of people to list of sales
.map((person) => person.sales)
// list of sales to a number
.reduce((total, sales) => total + sales, 0),
}));That's all there is to it. We just went through and turned all of the inner arrays into numbers. We didn't have to worry about anything else. The outer map creates a new object for each team, and that map uses an inner map/reduce to calculate one of its properties. You could extract the map/reduce into a separate function, and pass the array in. You could outsource the whole object construction to a separate function. Either of those is fine and frequently preferable. In this case, it's still small, testable, and doing one job.
Problem 2: Word-Counting
Let's say you're working on a primitive site scraping system, and the sub-problem you are working on right now is getting out of hand.
You are being handed sets of pages from an arbitrary site, and the data team wants a dictionary of each word that appears on any page, and the number of times that word appears anywhere on the site.
Soon, you're thinking about looping through pages, and in that loop, you're looping through lines, and then you're looping through words. This is exactly how I would have considered doing it in any language where I was expected to readLine.
for (let i = 0; i < pages.length; i += 1) {
// ...prep page and lines
for (let j = 0; j < lines.length; j += 1) {
// ...prep line and words
for (let k = 0; k < words.length; k += 1) {
// clean and lower-case and add to frequency map
}
}
}But what if we thought about this differently? For this feature, we don't really need an understanding of lines or of pages. The ask is really just for words. So we can start by thinking about how to arrive at one huge list of words, based on a set of pages given to us.
// concatenate two things together
// A.concat(B) returns an object of type A
const concat = (a, b) => a.concat(b);
// I don't care about lines. Just split on all whitespace.
const getWordsFromPage = (page) => page.trim().split(/s+/);
// Clean the punctuation off of a word.
const removePunctuation = (word) => word.replace(PUNCTUATION_REGEX, "");
// Increase the frequency of this word, in the dictionary.
const calculateFrequency = (dictionary, word) => {
const count = dictionary[word] || 0;
dictionary[word] = count + 1;
return dictionary;
};
// Give me one clean, lower-case list made up of
// all of the words on the site.
const words = pages
// lowercase the page, so the frequency is accurate
.map((page) => page.toLowerCase())
// turn each page into a list of words
.map(getWordsFromPage)
// turn the list of lists of words into a list of words
.reduce(concat, [])
// clean words
.map(removePunctuation);
// populate the dictionary
const frequencyMap = words.reduce(calculateFrequency, {});Well, we could. But as soon as we concatenate all of those together, into one big string, it's no longer mappable.
// turn all pages into one big string
const page = pages.reduce(concat, "");
// lowercase and split into words
const frequency = getWordsFromPage(page.toLowerCase())
.map(removePunctuation) // remove punctuation from words
.reduce(calculateFrequency, {}); // populate the dictionaryNotice that we turn it into a string, and then turn it right back into an array, to continue on.
There's also the potential for a serious error in this example, depending on the formatting of pages of text.
If there is no whitespace at the start or end of any page, then the first word of a page will be added to the last word of the previous page. This can be solved with a slightly more complex reducer, but is a problem that we didn't have to confront in the naive, set-based case.
There's nothing wrong with this, it's merely a different way of looking at the solution of the problem. And hopefully, that's what this post has provided: a different way of looking at problems.
Learn More
If you're looking for more in-depth tutorials and learning opportunities, check out our various JavaScript training options. Better yet, inquire about custom training to ramp up your knowledge of the fundamentals and best practices with custom course material designed and delivered to address your immediate needs.





