

Does this problem sound familiar to you? You save a Word document as 'v1.doc', then make some changes and save the new version as 'v2.doc'. A colleague might email back some changes, then rename that document to 'v2John.doc' destroying the whole idea of a well-defined genealogy of documents. As the deadline approaches you save the document as 'final.doc', dreading the inevitable, ever-growing 'finalfinal...' as hectic last minute changes are made.
It is surprising that this is an experience that many data scientists and machine learning engineers still share. But unlike text documents, datasets can easily take up gigabytes of space. Multiplied with the number of distinct processing steps and their variations, this can grow rapidly to a level where the dreaded 'out-of-space' warning hits the poor data scientist. And you know what Murphy's law says, anything that can go wrong will go wrong - typically right before a critical deadline.
Why does this happen? Data scientist often find it is hard to decide which dataset to delete, as they may be unsure which one was the latest or if it is still needed. Most datasets are still processed as files with precious little meta-information available besides creation dates and the filename itself. There is often no easy way to determine by what processes and with what parameters a file was generated. As a consequence, a disproportionate amount of time is spent on managing intermediate data artifacts and storage space.
I call this the “Proliferating Data Artifacts” anti-pattern. An anti-pattern is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive. Like our Word doc. example above, data scientists usually start with good intentions to avoid the proliferation of data artifacts. However, in the spirit of a classic anti-pattern, these intentions are usually quick to be abandoned in order to 'save time' when seemingly more urgent problems arise.
Pipelines to the Rescue
But as with every anti-pattern — there is a solution! Pipelines. Pipelines manage intermediate datasets under-the-hood. Essentially, they're a directed acyclic graph that describes the step-by-step processing of the data.
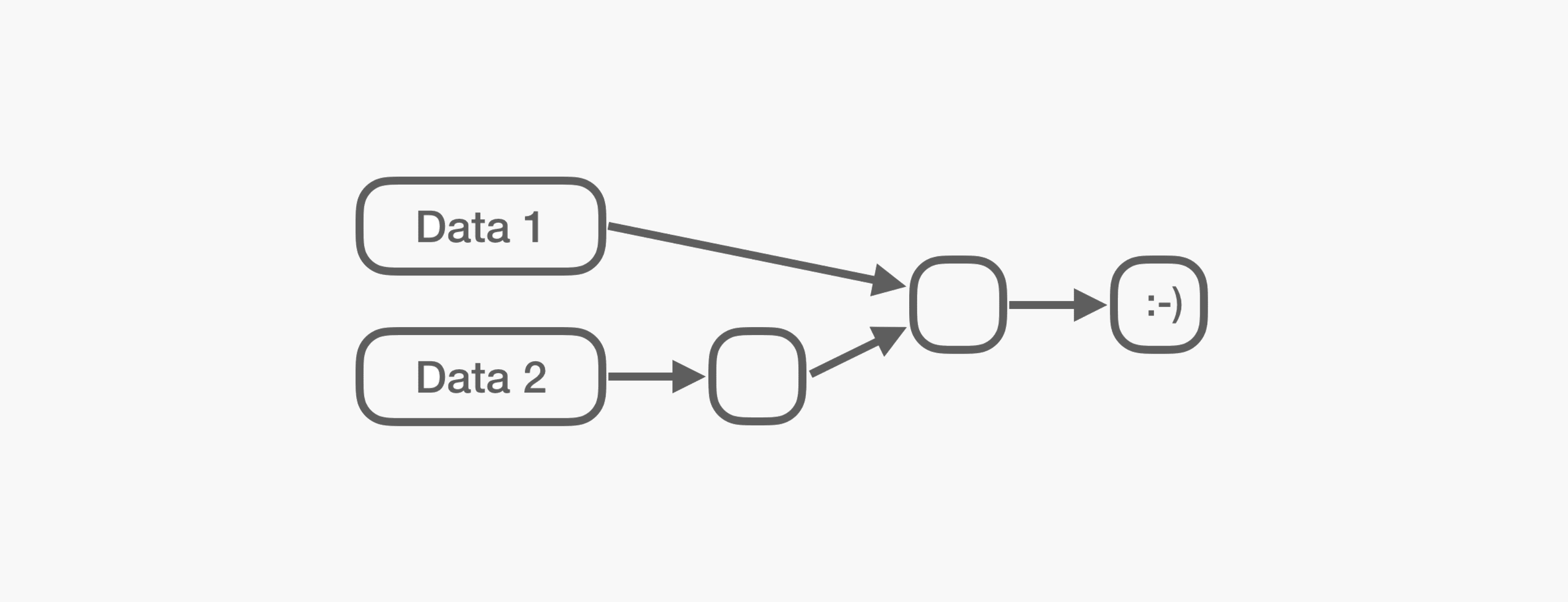
It's easy to see that any data artifact could be recreated by applying all of the processing steps that link it to the preceding data. All that's needed is the input data and a well-defined pipeline.
The pipeline approach has several advantages:
- The user does not need to track, save, or pass on (large) data artifacts. It's the job of the pipeline framework to track the intermediate datasets as they can be produced. The user no longer has to spend time devising a clever naming scheme or managing disk space. The pipeline can automatically delete files that are no longer needed.
- Unnecessary re-processing of unchanged/unaffected data artifacts is avoided because the pipeline can determine the datasets that are affected by a change in one of the processing steps.
- A pipeline is defined in code and can be versioned. This is a huge benefit for a pipeline that goes into production. Changes to the processing are documented by commit messages and associated with authors. This helps with deploying changes confidently and reverting to earlier pipeline versions when problems arise.
- There are many more advantages that a good pipeline implementation can offer, including parallel processing of independent parts of the pipeline, being self-contained, restart after failure, and efficient propagation of data changes.
So, now that you're filled in on all the advantages of pipelines there's no excuse not to use existing pipeline frameworks (or implement them yourself) and delete those proliferating data artifacts!
Interested in how Rangle leverages AI to create unique customer experiences to help you achieve goals faster, and surprise and delight users? Learn more, here.