

Have you ever wondered what it would take to have a Node.js application deployed to AWS? And how much longer it would take to build out a highly available, redundant environment with failover capabilities that supports zero downtime deployments? In this tutorial, we will create a highly available and fault-tolerant architecture for deploying a Node.js application. We will then integrate this with Elastic Beanstalk and build out a CI/CD pipeline to support a smoother and faster development process.
While there are many different ways to do that, this tutorial will take you through one of the easiest and most effective ways to achieve this goal all within an hour or less.
This will be done in two steps:
- Provision an Elastic Beanstalk environment using Terraform
- Configure a continuous deployment process using Jenkins
Overview
First off, let’s discuss some of the terminologies used in this post as well as some background on the tools used, and also do a quick overview of what we will build out. Feel free to skip this section if you want to jump right in and get your hands dirty (see pre-requisites) or gloss through the bold notes for a quick read.
Terminology
Autoscaling is the mechanism by which you can automatically spin up (or down) additional compute instances to maintain a steady level of performance to match traffic patterns based on predefined rules i.e. cpu level on instances, network latency, throughput etc.
Availability, also known as uptime, is the amount of time in which a system is in a functional state. This is usually measured as a percentage. In a highly available system, the goal is to have an application that is always available (or to have zero downtime).
Redundancy is the duplication of critical components of a system to increasing reliability. If your AWS autoscaling group has a minimum of 1 instance, then your system is not redundant and may be prone to availability issues.
Failover is the ability to switch over to a redundant system, component, or instance in the event of a failure of one of the systems, components or instances. Having redundancy and secondary or slave instances as a failover option will improve your fault tolerance.
CI/CD stands for continuous integration and continuous delivery or deployment. Continuous integration is the practice of merging, building and testing developers work multiple times a day with the purpose of promoting collaborative development and early bug detection. Continuous delivery is the practice in which an application is released with greater speed and frequency. In a similar sense, continuous deployment implies automatically releasing to production after it passes a series of tests. You cannot have continuous deployment without continuous delivery.
What is Elastic Beanstalk?
Elastic Beanstalk is one of the many services that AWS provides. With Elastic Beanstalk, you can quickly deploy and manage applications in AWS cloud by simply uploading an application. Now when I say "simply uploading an application", there are a few steps that you would need to go through if you want to have high availability, redundancy, and deployments with zero downtime; additional work will also be required to customize security, network, database, monitoring and alertings settings and the like. In this tutorial we will leverage Elastic Beanstalk for managing the application while customizing some of the settings to set up a typical multi-tiered production environment. Here is a list of some of the other areas that you can customize using the console:
- Software
- Instances
- Capacity
- Load balancer
- Rolling updates and deployments
- Security
- Monitoring
- Notifications
- Network
- Database
- Tags
Although we could go through each of these categories by hand to configure settings, why not strive to adopt DevOps best practices in automating (almost everything) to:
- Manage infrastructure as code
- Quickly scale and build repeatable, and consistent environments
- Centralize configuration
- Save time to focus on other problems
To do this we will use Terraform.
What is Terraform?
Terraform is a tool provided by HashiCorp for managing “Infrastructure as Code”. Although we could have done this using AWS's native CloudFormation (or other software), in this tutorial we will be using Terraform to build out the Elastic Beanstalk infrastructure. This tutorial assumes some basic understanding of Terraform and will not go indepth into the internal workings or best practices. They have very good documentation so check out their site for more information.
What is Jenkins?
Jenkins is a continuous integration and continuous deployment/delivery tool. It has been around for quite some time and has hundreds (at least 1000+) plugins available for it. I would not do it any justice describing it's possible uses here. You can find numerous online docs that talks to CI/CD setup for almost any combination of languages and source code repositories using pipelines, as well as automating other routine development tasks. In this tutorial, we will be using Jenkins and the AWSEB Deployment Plugin for continuous deployment.
Putting it Altogether
Terraform will provision an environment that you will typically find in most production setups today. It will be multi-az for high availability and have separate subnets for security. The application and database instances will reside private subnet - which may not be ideal for development, however a public subnet is also created from which you can provision a bastion host or add your own reverse proxy for more complex or custom scenarios. An S3 bucket will be set up to store access logs, as well as a custom cloud watch metric to notify on application errors. Finally, Jenkins will be integrated to build and deploy our application to our new infrastructure.
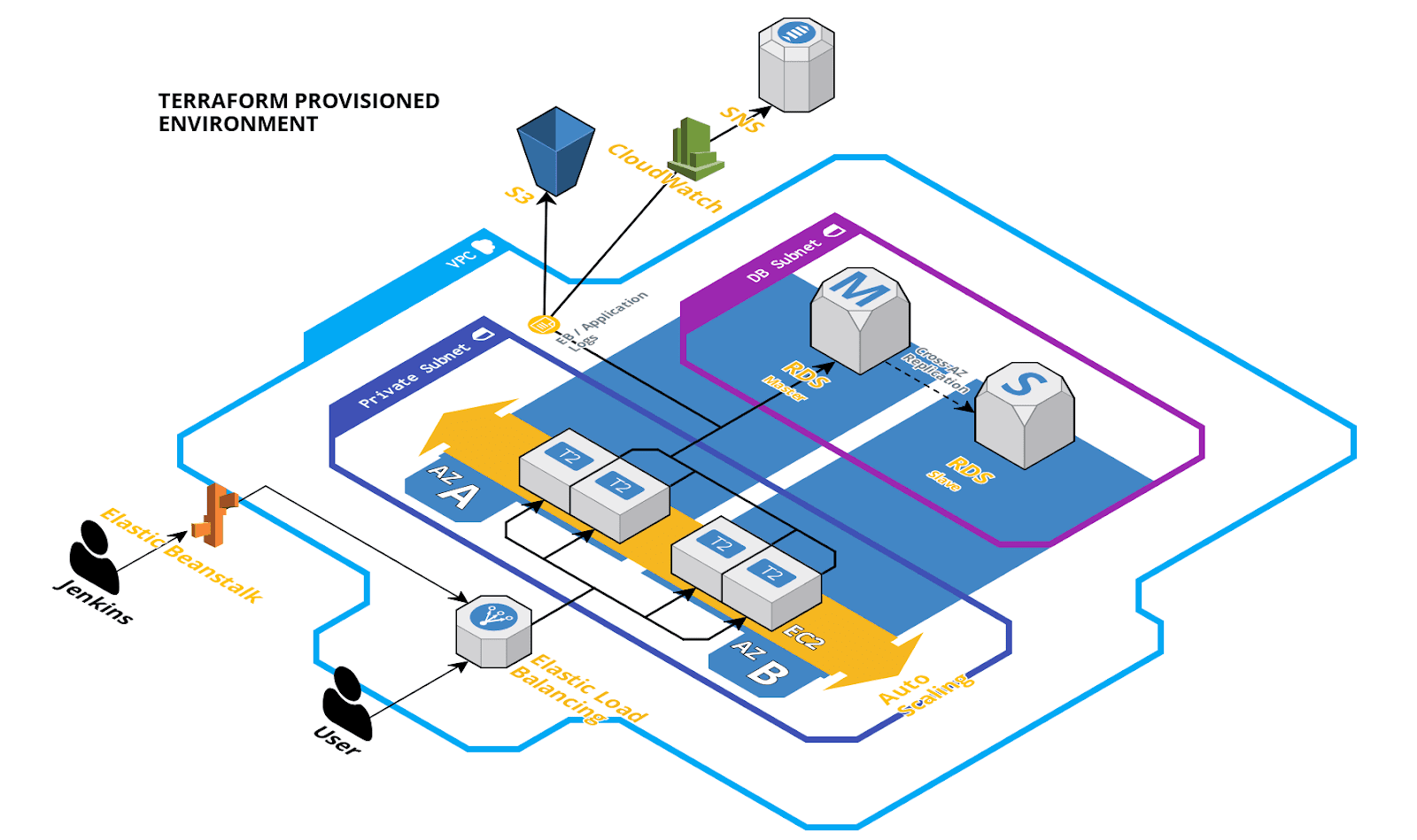
Pre-requisites
Before you start, you will need the following:
- Download a copy of the sample application source bundle: git@github.com:rangle/tutorial-eb-node-app.git
- Download a copy of the Terraform scripts: git@github.com:rangle/tutorial-eb-node-terraform.git
- You will also need an AWS account with sufficient privileges to create a programmatic user, roles, and keys.
- Download and install Terraform. As of writing this tutorial, the version that I am using is v0.11.7.
- An existing Jenkins environment with sufficient privileges to install plugins and configure builds.
- A GitHub account.
Terraforming Elastic Beanstalk
Setting up AWS
Before we can run the Terraform scripts, we will need to prep a few things in AWS.
First, we will need to create an AWS user that has programmatic access to provision the Elastic Beanstalk environment through Terraform. For the simplicity of this tutorial, we will grant this user full access to Elastic Beanstalk, RDS, S3, and CloudWatch. In a real-world scenario, you should follow the principles of least privileges to further refine permissions to only what is needed. Refer to the following for IAM best practices and conditions that can be applied to custom policies.
- Go to IAM Services > Users > Add User
- Give the username i.e. tf-eb-user
- Select "Programmatic access" and click "Next: Permissions"
- Attach existing policies directly:
- AmazonRDSFullAccess
- AmazonS3FullAccess
- CloudWatchFullAccess
- AWSElasticBeanstalkFullAccess
- Review and create the user
- Download and save the credentials file to a safe place.
Next, we will also need to create two service roles - one to manage the Elastic Beanstalk application and health monitor, and another to manage the EC2 instances.
- Go to IAM Services > Roles > Create Role
- Select "Elastic Beanstalk - Customizable" role
- Review and create the Elastic Beanstalk service role i.e. aws-elasticbeanstalk-service-role
Repeat the above steps to create the EC2 service role i.e. aws-elasticbeanstalk-ec2-role.
Edit this newly created role, remove any associated policies and attach the following policies:
- AWSElasticBeanstalkWebTier
- AWSElasticBeanstalkMulticontainerDocker
- AWSElasticBeanstalkWorkerTier
Lastly, we will create a set of EC2 keys - you will need this if you want to EC2 instances.
Go to EC2 Services > Key Pair > Create Key Pair
Give the key a name i.e. rangle-nodecd-ec2-key
Note that if you change the key name, it should be of the format < client>-< project>-ec2-key to match the reference in the Terraform scripts.
Reviewing the Scripts
Now that the AWS user, roles, and keys have been setup let's review the Terraform scripts. The folder structure should look similar to the following:
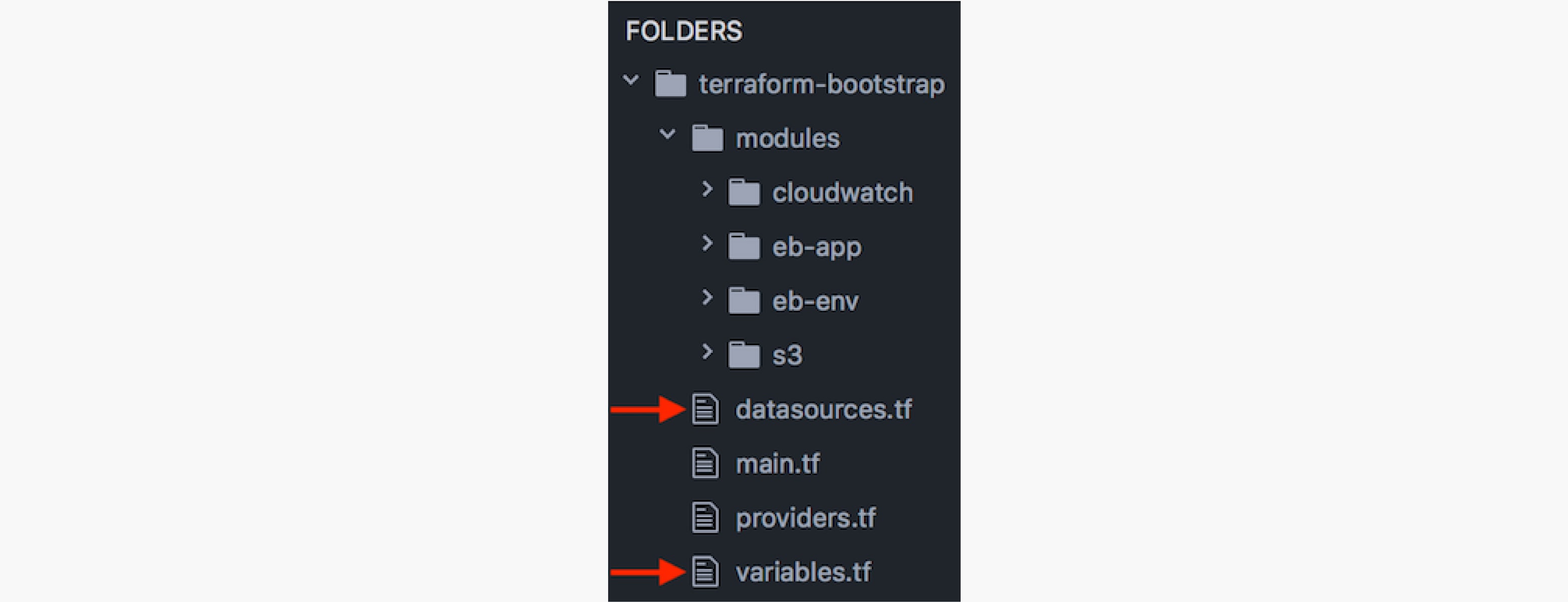
Take note of the following files:
- variables.tf
This file defines the client, project, and env variables that will be used for tagging and naming of some of various resources. - datasources.tf
Review and update the parameters in this file as needed. Make note of the EC2 key name, as well as the service role names and ensure that these match the values that were previously created in setting up AWS. - main.tf
This file is the main entry point for Terraform that uses the AWS provider to setup our Elastic Beanstalk environment. This also sets up an RDS MySQL database to integrate with your application. The following environment variables will be exposed to the Node process:
DATABASE_HOST
DATABASEPORT
DATABASE_NAME
DATABASE_USER
DATABASE_PASSWORD - s3 module
This module creates an s3 bucket for access logs . - cloudwatch module
This module is used to watch the nodejs application logs for errors, exceptions, and failed messages and then publish these notifications to an SNS topic. From here you can create your own subscribers to pick up and handle the errors accordingly.
Getting Down to Business
With the AWS setup and environment variables defined as needed, let's provision the Elastic Beanstalk environment.
Assuming you already have Terraform installed, switch to the terraform project directory and run:$ terraform init
This will initialize the necessary modules and plugins. Look for the success message:Terraform has been successfully initialized!
Next, generate the plan that will be used to build the environment. Update the command with the access and secret key of the AWS programmatic user that was created earlier.
$ terraform plan -var "aws_access_key=$AWS_ACCESS_KEY" -var "aws_secret_key=$AWS_SECRET_KEY" -var "aws_region=$AWS_REGION" -out terraform.tfplan
In the generated output you should see 41 items to add. Now apply the plan using the following:
$ terraform apply terraform.tfplan
$ terraform plan -var "aws_access_key=$AWS_ACCESS_KEY" -var
"aws_secret_key=$AWS_SECRET_KEY" -var
"aws_region=$AWS_REGION" -out terraform.tfplanAfter about 5-10 minutes, you should have a fully functional Elastic Beanstalk environment running with a sample application. From the Terraform Outputs, use the Elastic Beanstalk cname in a browser to verify that the sample application is running.

Connecting the Pipes
What good is an application without a backend database. Let's swap that out now with another application that has database connectivity. To do that we will setup a continuous deployment process using Jenkins.
Reviewing the Application
The sample application that we will be using is based upon another tutorial "setting up Node.js with a database". This application will give us a basic method for creating users and authenticating against a MySQL database from Node using Knex.
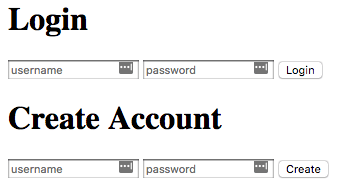
The application manages the database connection settings in knexfile.js - which will ultimately read from the environment variables that were previously created through Terraform. If you examine index.js, you will see that the application has two routes: one for login and one for createUser. The login function will try to authenticate the username and password against what is stored in the database and return a success or failed message. The createUser function will add the user and encrypt the password before storing in the database, only if the user does not already exist; it will not update the credentials for an existing user.
After reviewing the application let's initialize the project and commit to a repository that we will use for continuous deployment.
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin git@github.com:<myrepo>.git
$ git push origin master
With our repo setup, let's move on to configuring Jenkins.
Setting up Jenkins
Although the Jenkins job/pipeline could be configured using an agent that has Elastic Beanstalk CLI and other build tools, for simplicity we will be using the AWS Elastic Beanstalk Deployment plugin and configuring a freestyle project. The remaining steps assumes you already have an existing Jenkins instance with node/npm installed on the master or slave agent.
- If the plugin isn't already installed: Go to Jenkins > Manage Jenkins > Manage Plugins and install it.
- Add AWS credentials to Jenkins. This can be the same credentials that were used with Terraform or another set of credentials that has permissions to deploy to and update an Elastic Beanstalk application.
- Add the GitHub keys that were used to set up the previous repository.
- Create a "Freestyle project" and configure the following:
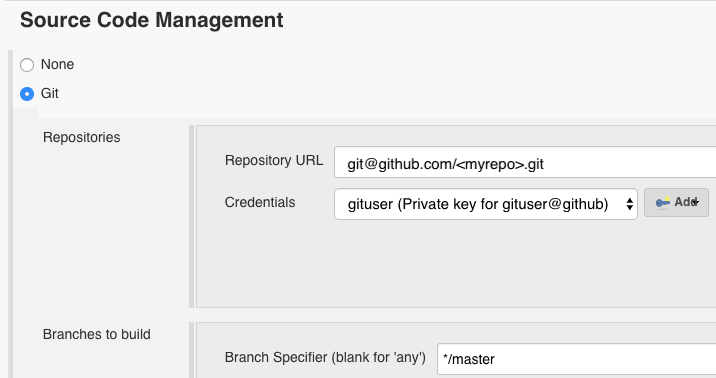
- Update SCM with the correct repository URL, credentials, and branch.
- Update SCM with the correct repository URL, credentials, and branch.
- Add a remote build trigger.

Configure a webhook in GitHub for your project.
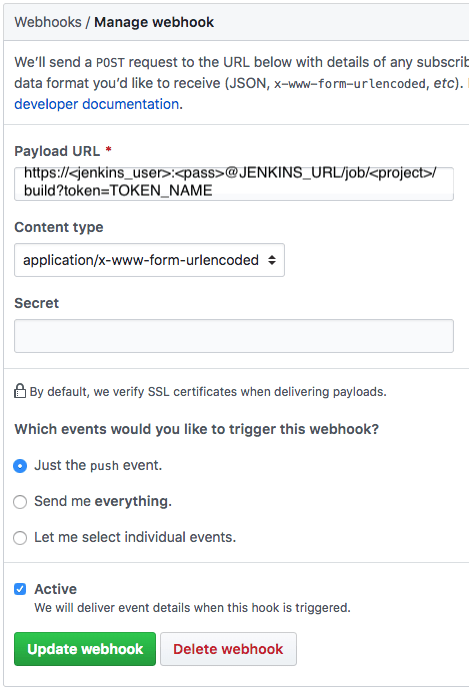
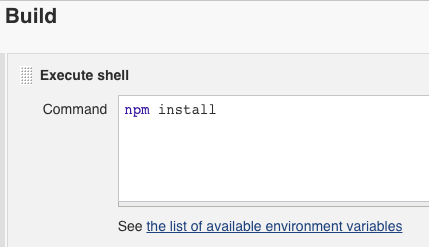
- Add a build step to build the application.
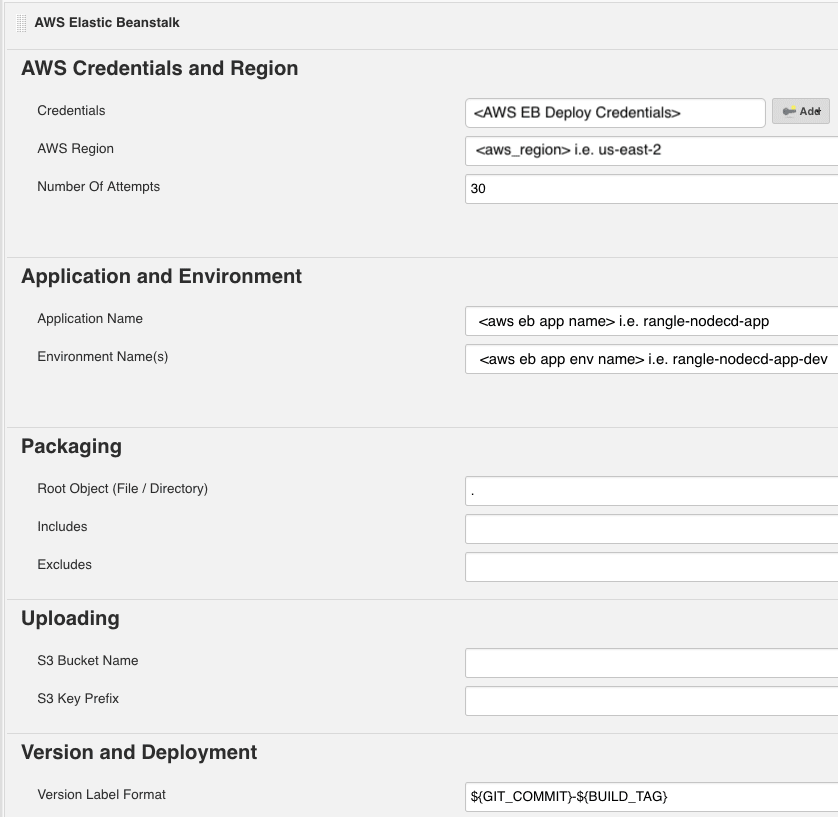
- Add "AWS Elastic Beanstalk" as an additional build step to complete the deployment.
- Save your changes and an initial build should kick off.
Opening the CI/CD Pipeline
Let's get things flowing. Make an update to your application, commit the changes and push the change to master. You should see the build job automatically trigger. And if everything was configured correctly, the application will be packaged, versioned, and deployed to your Elastic Beanstalk environment within a few minutes. Hit the Elastic Beanstalk cname again in a browser and marvel at your work. Congratulations! You did it!
Cleanup
To avoid any unexpected costs you can deprovisioned the Elastic Beanstalk environment by running the following command with the appropriate variables:$ terraform destroy -var "aws_access_key=$AWS_ACCESS_KEY" -var "aws_secret_key=$AWS_SECRET_KEY" -var "aws_region=$AWS_REGION"
What's Next?
Now that you have completed this tutorial you should have a foundation from which you can continue to build upon. Treat the Terraform scripts as code, version them and use it as a starting point to build an immutable infrastructure. Customize it to meet your application requirements and use it to provision multiple environments. Look out for future posts where we will build upon this and perhaps even integrate with a Kubernetes cluster.
For continued learning, why not explore more about Elastic Beanstalk and the various options that can be configured; dive into Terraform to see what other modules are at your disposal; or expand the Jenkins build job with a more robust pipeline.
Below are some additional resources to help get you started: