



When we think automation, we think digitization. But ironically, the digitization of text is not enough to automate the tasks we care about. It might seem simple to extract information from web pages, PDF forms, emails, and word documents, because they can be easily read by a computer. However, the unstructured nature of most text documents effectively locks their information away from straightforward automatic processing.
Consider an employee who spends each day typing digital invoices into an accounting program. Each invoice may have dozens of values such as addresses, billed items, quantities, and prices that must be individually identified and copied. Wouldn’t it be so much better if an intelligent tool could automate this task?
Unfortunately, something as simple as extracting the address can be difficult to automate if the address can appear in different places and can be formatted in an arbitrary number of ways. This mundane task is still surprisingly challenging for computers, even though it takes a human less than a second to recognize the name, street, and postal code.
Intelligent Content Extraction (ICE) refers to a recent effort to use Artificial Intelligence to automatically find and extract information of interest (Figure 1). This could help accelerate especially those workflows that require the extraction of information from paperwork or scanned documents, such as invoices, application forms and resumes. By eliminating highly repetitive or cumbersome tasks, ICE can free up employees to focus on more valuable, creative work. However, implementing ICE in a way that works well and feels seamless isn’t easy.
In this post we offer tips to help you succeed at Intelligent Content Extraction. We’ll also look at two “out of the box” text extraction tools, what they actually give you, and how you might leverage them as a bootstrap.
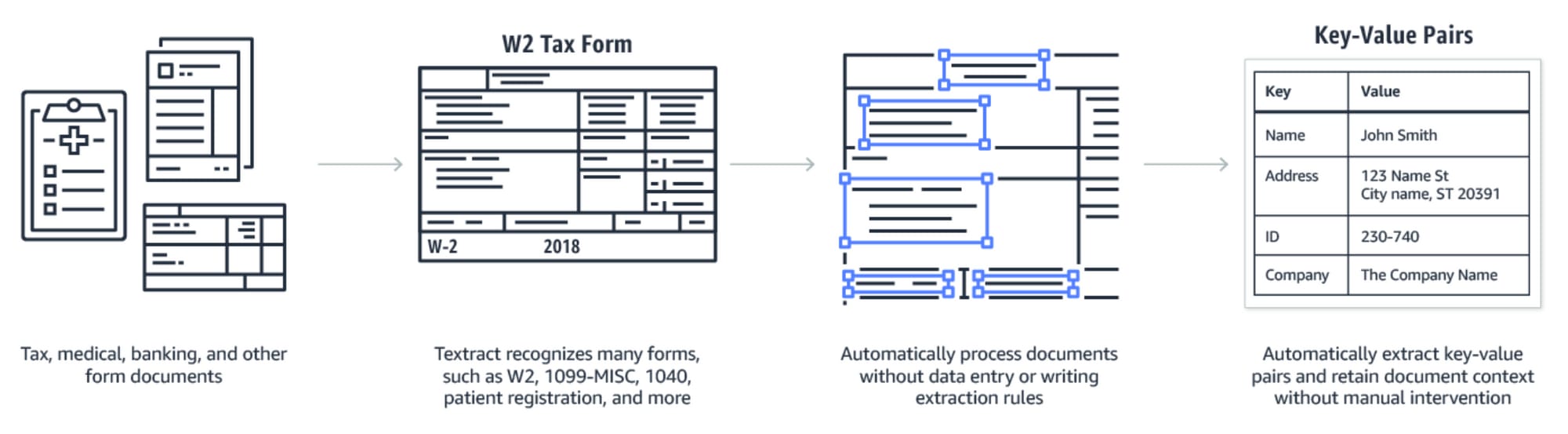
Figure 1: Widely-available approaches to document content extraction use optical character recognition (OCR) to extract text characters and then apply algorithms and AI to recognize key-value pairs, e.g. Name: “John Smith” or Address: “123 Main St”. [Image Source]
Know When to Use Templates
Unfortunately, a general purpose algorithm that can extract the right information from any document does not currently exist. Although it might be desirable to develop a solution that is as general as possible, it’s often more efficient to leverage the fact that in most cases, documents vary in a predictable way.
For example, fields like “passport number” or “date of birth” always appear in the same location on a passport. Although there can be regional differences, e.g. an American passport may differ from a Canadian passport, the number of variations is limited. In these cases, one can define a template for each type of document. A template tells your content extraction tool where to expect a certain field-value pair and how to map it to an internal data structure.
But what if your documents are unstructured or contain significant variation? For example, there are countless ways in which the value for “total amount due” on an invoice can be presented (Figure 2). If your documents aren’t standardized in their format, layout, and content (etc.), then templates won’t work. You’ll need a more sophisticated algorithm that generalizes well to unseen variations of the document. We’ll discuss how to approach situations that cannot be templated later in this post.

Figure 2: When templates fail. A collection of different ways the field “total amount due” can appear on an invoice. Such variation is poorly handled by simple template- or rules-based approaches. [Image Source]
Use Existing APIs to Get You Partway
Development of intelligent content extraction can be sped up by leveraging one of several competing “cognitive” APIs on the market, such as Amazon Textract or Microsoft Azure Form Recognizer. Let’s take a closer look at when you might use these.
Microsoft Azure Form Recognizer
If your use case fits a template-based approach, try Azure’s Form Recognizer. This works well if you know ahead of time what your documents will look like.
Preparation is straightforward. You provide Form Recognizer with at least five training examples of each type of form you expect. Based on what changes and what remains the same between these forms, Form Recognizer learns where to draw its bounding boxes to extract the values that change. In short, it creates an extraction template for each form type.
When you send Form Recognizer a document, it basically tries to match that document to one of the templates it has already created. It then follows the extraction rules defined by that template. The output is a JSON object containing key-value pairs and their coordinates (e.g Figure 3). The output can thus easily be further processed and added into a database, for example.

Figure 3: An example of a document (left) submitted to Microsoft Form Recognizer, and the extracted key-value pairs (right). Form Recognizer provides an out-of-the-box algorithm for processing sales receipts. It also allows you to custom-train a new template-based model for your own task, with the caveat that you need to provide a minimum of five example documents. [Source]
Amazon Textract
Amazon Textract is another API for intelligent content extraction. Textract’s OCR uses the same technology behind Amazon Recognition, which makes it more robust against variations in font (including scripts), lighting conditions, and the orientation of the text. The output of Textract provides the coordinates of all text within your document. It also tells you whether a text segment belongs to a page, line or word.
Textract can identify tables when rows and columns are clearly separated by dark borders (e.g. Figure 4). Its key-value pair extraction works well on a predefined set of common forms, such as W2 or 1099-MISC tax forms. But for other documents, although Textract sometimes correctly identifies fields such as “Invoice Date” and “Balance Due”, its built-in key-value pair extraction is often not enough.
For example, consider a more complex document such as a restaurant menu. Suppose we want to make it easier for a restaurant owner to onboard onto an app such as Grubhub, Seamless, or Uber Eats without having to manually type up their whole menu. The goal would be to identify and extract all menu items, prices, descriptions, and the categories (e.g. “Appetizers”) that each item belongs to. In Figure 5, we see that Textract is quite good at identifying most text within the document. However, in this case the built-in key-value pair extraction only identifies the fields “imported” and “bottled beer” (Figure 6).
The takeaway? Textract is great for OCR and extracting content from standard-looking tables. But for more general document types, if you cannot use a templating approach (e.g. with Azure Form Recognizer) then you’ll likely need to write your own algorithm.
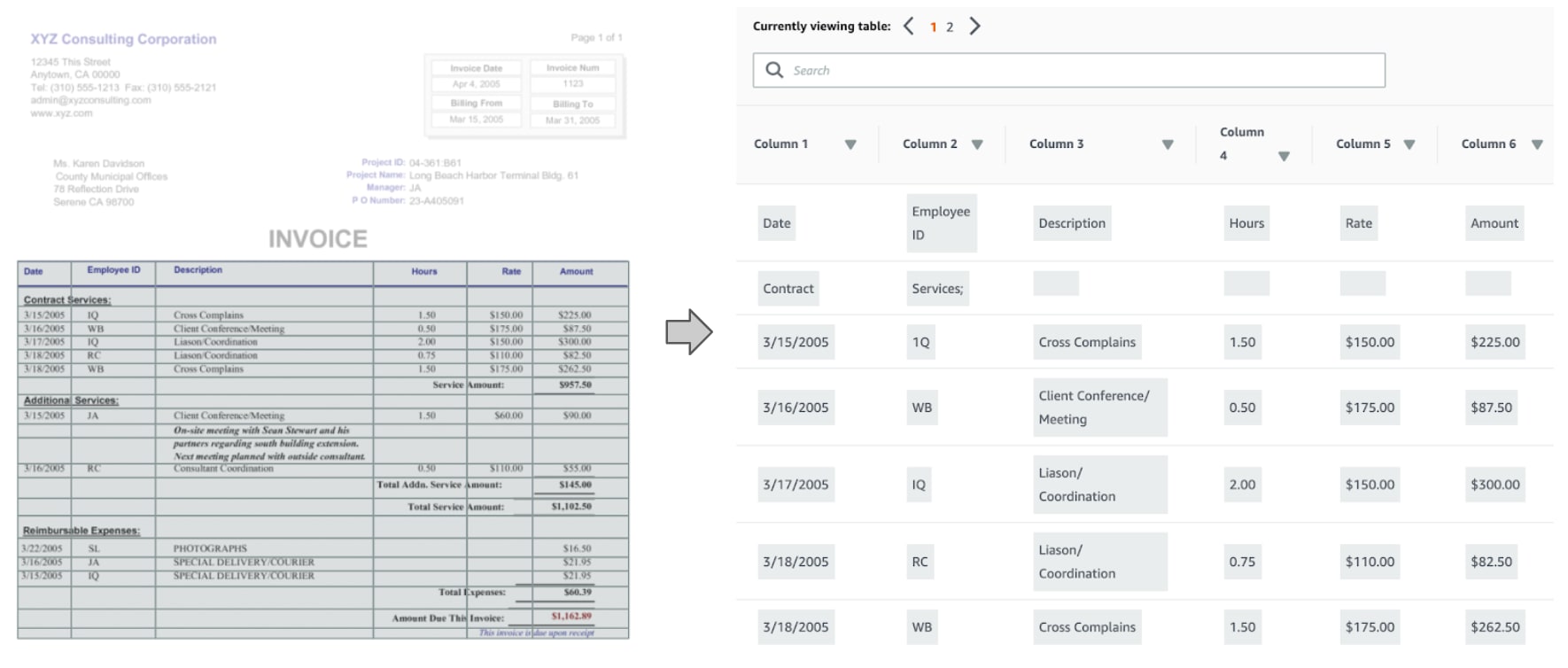
Figure 4: An example of Textract applied to a simple form, where it successfully identifies a table and groups its text contents into rows and columns.

Figure 5: An example of applying Amazon Textract to a restaurant menu. The document is shown on the left. The grey highlights indicate where Textraxt has identified text. The right side shows the extracted text snippets. [Menu Source]

Figure 6: Example of Textract’s out-of-the-box attempt at key-value pair extraction for an uploaded menu. Textract was applied to the entire menu, but succeeds only at identifying two text sub-groupings for “bottled beer” and “imported”.
Combine Top-Down with Bottom-Up
One reason why Textract fails on the menu example is because it lacks an inherent understanding of the hierarchy that relates different text snippets. For example, it has no built-in way of knowing that “domestic” and “imported” are subsets of “bottled beer” (Figure 6). It likewise doesn’t know that each food item (e.g. “spicy buffalo wings”) belongs to a particular heading (“first bites”), and that each food item should have a description and price.
In general, if we give our algorithm the ability to identify the hierarchy of text, we can help it interpret the contents of our document and where to find values of interest. In fact, content extraction on a menu amounts to segmenting the text into related blocks and then fitting these onto a hierarchical tree, where a menu may have branches for each heading, headings have branches containing food items, and each food item has branches for item name, item description, item price, and so forth. Below are some strategies that can help you succeed at identifying the text hierarchy.
Start with Top-Down Approach
Imagine you are manually searching for something within an unfamiliar document. How do you proceed? Rather than reading the document from start to finish, word by word, you find information by looking at the document as a whole, and then use clues from the document layout to narrow your search down to a few key locations.
We can take a similar approach with our algorithm. Create bounding boxes based on similarities in the text’s horizontal and vertical alignment. Amazon Textract does this to identify lines, but we can go further. For instance, group lines that share horizontal left-alignment and an uninterrupted vertical spacing into paragraphs. Bounding boxes might be nested, which can help build a better picture of the text hierarchy. Clustering text into ‘blocks’ based on layout will help you simplify the problem. Grouping rows of text into paragraphs and paragraphs into sections can help assign order and meaning.
Even without reading any text, a document’s visual grammar can provide clues about the purpose and organization of its contents (see Figure 7). Detection of font style and size can help. For instance, a line of text that is bolder and larger in font might be a title or heading, conveying information about text hierarchy. Detecting border lines and large gaps can help identify separate “regions” of related text. Detecting repeating patterns in text format and position can provide additional clues.

Figure 7: A document’s visual grammar can provide clues about its semantic structure, even without reading any text.
In Figure 7(a), we might know from our use case that a name and address tend to appear early within the document, often within the top-right or top-left corner and separated from the rest of the text. Based on this document’s visual grammar alone, we might therefore infer that the text block in the top left-hand corner has a high probability of containing a name and address. We might also ascribe the larger bolder lines as being probable candidates for section headers, and segment them separately from the smaller non-bolded lines below each. In Figure 7(b) we might infer that the column of sparsely-spaced lines on the left contains enumerations or sub-headings that can be used to segment the text within the column on the right.
A document’s layout and visual grammar not only lets you subdivide it into discrete regions of related text, but is also useful for determining the hierarchical relationship between these regions. For example, we could discern in Figure 7(a) that “Paragraph 1” is a child of “Header 1”, since blocks that are closer in proximity are more likely to be related, and large bold fonts are likely to be higher in hierarchy than smaller lighter fonts. Text blocks that share similar font style and size (e.g. “Header 1” and “Header 2”) are likely on the same level of hierarchy.
Refine with Bottom-Up Approach
The goal of the bottom-up approach is to better understand what is inside the regions of interest or text blocks identified by the top-down approach. This can validate, refute, or refine hypotheses formed by the top-down approach. This can be as simple as scanning the text for keywords. For example, detecting the words “Street”, “Court”, or “Lane” can add confidence that a text block contains an address. Recognizing parts-of-speech can also provide clues about where a text block sits within the document hierarchy. For example, you might know that a text block containing a menu item description tends to contain a lot of adjectives.
A more powerful approach is to use entity extraction, which can be trained to use context and patterns to identify values. One example is recognizing that a ten-digit number such as (555) 555-5555 located near a name or address is likely a phone number. There are several existing Natural Language APIs you can leverage to identify common entities such as addresses, phone numbers, and prices. However, these APIs are not trained to detect domain-specific entities. For our menu example, how do you tell the difference between a food item (“peppercorn steak”), a food heading (“Entrees”) and the food description (“served with potatoes and gravy”)? For this you will need to train your own custom entity-aspect extraction model. In this case, that means manually labelling all the entrees, food items, and descriptions from a large collection of menus. Fortunately this process can be sped up by outsourcing annotation to a pool of human workers through Amazon GroundTruth or Google’s AI Data Labelling service.
Start with Augmentation, Not Automation
During the early stages of product development, beware of over-investing in the algorithm. You don’t have to build everything in a lab, nor should you. For your first release, find quick wins that already deliver value to the user while collecting feedback to guide your feature development and data strategy. The key is to shoot for augmentation, not automation.
If developing an app to help users digitize their menus faster, you might initially ask the user to draw a box around one menu heading, one food item, and one food description, such as in Figure 8 below. Your algorithm could then recognize that the orange text with larger font corresponds to the menu headings (e.g. “flavourful flatbreads”), the bolded black text corresponds to the food item name (e.g. “the eden”), and that a food item’s description tends to contain the “|” character and is located immediately below the food item name. You could apply this strategy to any document with repetitive structure; for example, the digitization of a course catalogue, where a user might need to extract each course title, course code, description, prerequisites, and number of credits.

Figure 8: An example of recruiting the user to aid segmentation in repetitive documents. On the left, the user has drawn a box around one heading, one food item, and one item description. On the right, the algorithm uses patterns identified from the user’s segmentation to automatically segment all other instances of headings, items, and descriptions.
An example of recruiting the user to aid segmentation in repetitive documents. On the left, the user has drawn a box around one heading, one food item, and one item description. On the right, the algorithm uses patterns identified from the user’s segmentation to automatically segment all other instances of headings, items, and descriptions.
Imperfect accuracy is not a blocker. A well-designed user experience can compensate for imperfect accuracy. If you have multiple candidates for a key-value pair, show them all to the user and make it easy to select one. If you cannot pinpoint the precise location of a key-value pair, you can still show the user snippets of the document showing the regions where it is most likely to be, and then allow them to select the correct value or narrow the search by drawing a box.
Give users the opportunity to review extracted content and provide corrections where necessary. If your tool makes a mistake, the user’s correction can be collected to re-train and improve your algorithm. As the amount of training data available to you through your app increases, you might eventually achieve an accuracy where full automation is feasible. However, your users may still wish to verify the output until your solution gains their trust.
Make it easy to correct mistakes. For a document with a nested hierarchy such as a menu, the verification step might include a drag-and-drop interface as in Figure 9. If a menu item is under the wrong heading, the user simply drops it under the correct one. Show orphaned text, such as a menu description that wasn’t grouped with a food item, so that the user can easily merge this with the correct item. If a food item is missing its description, provide a visual indicator that makes this easy to spot.

Figure 9: An example of a validation screen for an app that extracts the contents of a menu. The left panel shows the extracted menu items grouped by their hierarchical relationships. Text that was not successfully grouped is shown in the panel on the right. In this case, the user is alerted that the item “BBQ Chicken” is missing a value for price ($8.95). The correction can be made by selecting “+ Add Tag” to create a new price block and then typing in the value, or by dragging-and-dropping the text block containing $8.95 from the panel on the right.
An example of a validation screen for an app that extracts the contents of a menu. The left panel shows the extracted menu items grouped by their hierarchical relationships. Text that was not successfully grouped is shown in the panel on the right. In this case, the user is alerted that the item “BBQ Chicken” is missing a value for price ($8.95). The correction can be made by selecting “+ Add Tag” to create a new price block and then typing in the value, or by dragging-and-dropping the text block containing $8.95 from the panel on the right.
Measure Your Success
When it comes to proving value and deciding how to invest further efforts, nothing speaks better than hard data. Define success metrics from the project onset and have a plan in place to measure them. The importance of getting feedback early cannot be overstated. Data driven decisions will help you build a better product, faster. Plus, evidence of early wins will help build your team’s momentum and unlock budget.
Measuring model accuracy is standard practice, but it isn’t the whole story since the design of the user experience also plays a big role. What you are really after is how both model and user interface come together to save the user time. So measure things such as the time spent completing the task, and the number of times the users need to intervene with corrections or manual entry. If this is part of an app’s onboarding process, measure the drop-off rate, to see if more users who begin the onboarding flow are now completing it.
If your goal is to improve customer experience (CX), make it easy for the user to provide immediate feedback so you can score your augmented workflow on customer satisfaction and customer effort. For example, you might ask the user to rate their experience on a 5-point scale as seen in Figure 10.

Figure 10: An example of a simple user survey to generate a customer satisfaction score (left screen) or a customer effort score (right screen). Aim to collect user feedback within the app itself, while the user’s recollection of the experience is still fresh.
An example of a simple user survey to generate a customer satisfaction score (left screen) or a customer effort score (right screen). Aim to collect user feedback within the app itself, while the user’s recollection of the experience is still fresh.
When improving employee experience (EX), measure adoption rate. Let employees initially choose whether to use the augmented workflow, and see what fraction continues to use it. Compare productivity with and without workflow augmentation. How many documents are being processed per day? What is the average time spent per document? Ask your employees whether they feel more productive or more satisfied with their task.
Summary
Intelligent Content Extraction can provide tremendous value despite its challenges. You can be smart in your approach to maximize your chances of success in a few ways. You can leverage existing cognitive APIs to speed up development, but these are not complete solutions. If dealing with standardized forms or documents with low variety, use templates. Otherwise, combine top-down and bottom-up approaches to establish a semantic understanding of document content. But don’t over-invest too early in the algorithm. Clever design of the user experience is a key part of the solution. You can deliver value even without a perfect algorithm. The sooner you deploy a solution to the user, the sooner you can measure its impact and make data-driven decisions about how best to focus your efforts. However you choose to do it, measure success and obtain feedback early and often. Gathering data helps you avoid the pitfalls of premature optimization or focusing on the wrong improvements. Build, measure, learn, iterate. And before long, you’ll be reaping the rewards of boosted productivity and happier users.
Interested in learning more about Artificial Intelligence at Rangle? Visit us at https://rangle.io/artificial-intelligence/