It's been a couple years since GraphQL has been released. You've heard the buzz and maybe watched a couple talks, but haven't had the chance to spin up a server and try it out for yourself. The ecosystem can be a little intimidating at first. You may have even wondered what you stand to gain by adopting GraphQL.
GraphQL can help you:
- Reduce the amount of network traffic between the client and server
- Reduce the size of network traffic between the client server
- Centralize your API
- Share your API
- and much more..
One of the inconveniences associated with REST is having to make multiple client-based calls to retrieve related data. For example, if you wanted a list of posts made by a particular user and details for each post, you'd be making at least two calls; one for the user that will fetch their post IDs and a second for the details of each post.
api/user/{id} // returns the user object with an attribute: posts=[1, 2, 3]
api/posts?id=[1,2,3..] // or worse api/post/{id}The client must now handle waiting for the post IDs to be returned before making the second call and when all data is returned, transform into a format that suits the business needs. This becomes even more tedious when the client wants to specify a different set of fields returned based on the use case.
With GraphQL this scenario can be handled with a single query to the server with the built-in flexibility to specify the desired fields, including nested fields. While GraphQL can reduce client side complexity, it is important to understand that it does not promise any speed increases over REST. Said query could look something like:
{
user(id: 123) {
posts {
date
length
comments
}
}
} This blog takes a brief look at what's needed to wrap a REST endpoint and assumes no prior GraphQL experience. By the end I hope to have inspired you to take a deeper look at GraphQL schemas, queries, and resolvers, and how you can apply these concepts to wrap a REST endpoint and harness the power of GraphQL.
A common and easy use case for developers that would like to leverage the power of GraphQL is to wrap an existing REST API. This approach allows for parallel development of the new and legacy server, no downtime for consumers, and when complete, can reduce the client side traffic - a big win for mobile users.
Introducing GraphQL Yoga
Building a GraphQL server is no small task for novice and experienced developers alike, there's a fair amount of complexity involved. graphql-yoga is a library that incorporates the best practices and configuration from the community, providing a way to jumpstart server development. Developed by the great team over at Prisma, it's built on an express and apollo-server, well established node server and graphql middleware libraries respectively, but also includes a few utility libraries to improve the developer experience. graphql-yoga has a number of config options that expose the underlying library that enable us to grow into our server without restricting our options later on.
We'll use graphql-yoga for its ease of use and minimal setup required to get a server up and running.
Setting Up GraphQL Yoga
GraphQL Yoga is a full-featured, batteries-included GraphQL server built on top of the popular apollo-server library and is the quickest and easiest way to get our server up and running.
We'll use it to quickly get a server up, create a fresh node project with yarn init, install GraphQL Yoga via yarn add graphql-yoga, and in your entry point (index.js) drop in this code:
/index.js
const { GraphQLServer } = require("graphql-yoga");
const typeDefs = `
### Enter schema here ###
`;
const resolvers = {
// ### Enter resolver here ###
};
const server = new GraphQLServer({ typeDefs, resolvers });
server.start(() => console.log("Server is running on localhost:4000"));Now we're ready to look at GraphQL. We'll be filling in our type definitions (schema) and resolvers as we go along.
Note: If you're comfortable with GraphQL schemas and resolvers, feel free to skip to the API wrapping.
First stretches: Getting up to speed with GraphQL
Schema
GraphQL leverages its own type language as a way to describe data objects in a way that is generic and not tied to any specific programming language. This gives schemas the power to be used as a single source of truth and consumed by various language environments without modification. Some developers feel that the schema adds unwarranted boilerplate but the self documented nature of a schema paired with tools like graphiql or graphql-playground make exploring your API a smooth and painless experience. It is perfect for on-boarding as it gives devs a sandbox to test your API without a long ramp up.
Let's take a look at an example schema that could be potentially used for a library:
type Query {
book(id: ID!): Book
}
type Book {
id: ID
title: String
author: String
publishYear: Int
}Not too scary right? book is a field we are defining on our custom Book type on which, we define a few more fields using the built in GraphQL scalar types. They are Int, Float, String, Boolean, and ID. These default scalar types can be thought of as variable data types.
(id: ID!) specifies that not only can we pass an id as an argument when querying for a Book, but that one is required because of the exclamation syntax. Query is our root query and represents all the entry points into our GraphQL API. This will become better understood as we start to run queries against the schema.
Query
Now let's look at how we would write a query for this schema to add some more context. In an application the query would be sent by a client to our server to request some data, but in our case we won't have a client to make a request so we'll just be testing it later in our browser using graphql-playground.
{
book(id: 1234) {
author
publishYear
}
}That's it. This query requests a book with the ID of 1234 and if a book is found, an object will be returned with ONLY the author and publishYear fields.
Resolver
So now we know how to use queries to ask for data, but how does GraphQL know how find the data we're looking for and return it? If you guessed "with resolvers!" you'd be correct.
Resolvers are functions that are called based on the object requested. Resolver functions are passed 3 arguments, 2 of which we'll include:
parent is the previous object accessed in the tree. We'll make use of this argument later in the post.
args is an object that holds all the arguments passed in the query.
Query: {
book(parent, args) {
return [
{
id: '1234',
author: 'George Orwell',
title: '1984',
publishYear: 1949
},
{
id: '5678',
author: 'Ray Bradbury',
title: 'Fahrenheit 451',
publishYear: 1953
}
].find(book => book.id === args.id);
}
}As you can see, we use the id passed in the query to find our book and return it. In a real application we would hope to have the list of books returned from a database, a call to an external API, or possibly another source on our server outside of the resolver function. In any case, the pattern remains the same. We make a query and it is resolved through a function.
Running an example
Our code should look like this:
const { GraphQLServer } = require("graphql-yoga");
const typeDefs = `
type Query {
book(id: ID!): Book
}
type Book {
id: ID
title: String
author: String
publishYear: Int
}
`;
const resolvers = {
Query: {
book(parent, args) {
return [
{
id: "1234",
author: "George Orwell",
title: "1984",
publishYear: 1949,
},
{
id: "5678",
author: "Ray Bradbury",
title: "Fahrenheit 451",
publishYear: 1953,
},
].find((book) => book.id === args.id);
},
},
};
const server = new GraphQLServer({ typeDefs, resolvers });
server.start(() => console.log("Server is running on localhost:4000"));Returning to our GraphQL Yoga server, we can now add our schema and resolver function from above to index.js and run the server to test locally with graphql-playground.
yarn run start
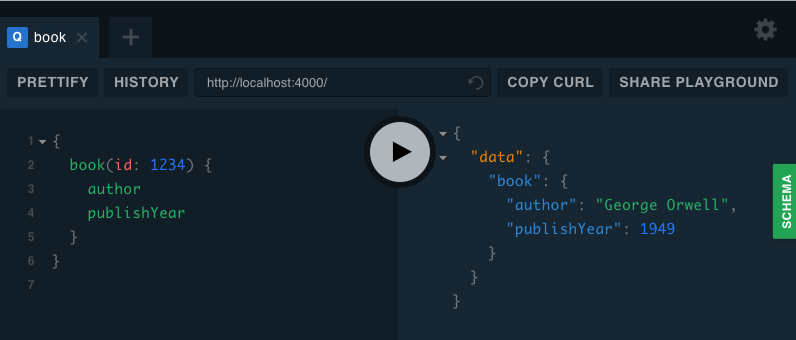
Navigate to http://localhost:4000 to access graphql-playground, it comes automatically bundled with graphql-yoga. In the left pane of the playground interface, enter the query below, and press the run button in the middle.
{
book(id: 1234) {
author
publishYear
}
}You should now see our book details resolved on the right pane like the picture below.
The REST API
So far we've used graphql-yoga to run our server and defined our schema and root resolver, allowing us to query our server for book details that lived in our resolver. That solution is far from ideal. Instead, we are going to retrieve our book information from the Open Library API.
To begin we're going to make some small changes to our schema:
type Query {
book(isbn: String!): Book
}
type Book {
isbn: String
title: String
author: [String]
publishDate: String
}We're going to allow for multiple authors to be returned for a book and change our publish year into a publish date. We've also changed our Id field to isbn to more accurately reflect how we will now be using it.
Our resolver should now look something like:
Query: {
book(parent, args) {
return axios.get(`https://openlibrary.org/api/books?bibkeys=ISBN:${args.isbn}&jscmd=details&format=json`)
.then(res => transformResponse(res.data[`ISBN:${args.isbn}`].details))
.catch(err => console.log(err));
}
}We're making a simple HTTP call using the axios library and passing the isbn argument as a query parameter. Once we get a response we'll pass it through a data transformer function and return the result to GraphQL.
Note: Don't forget to install axios with yarn add axios before running!
Our code should now look something like:
/index.js
const { GraphQLServer } = require("graphql-yoga");
const axios = require("axios");
const transformResponse = (details) => ({
author: details.authors.map((author) => author.name),
isbn: details["isbn_13"],
title: details.title,
publishDate: details.publish_date,
});
const typeDefs = `
type Query {
book(isbn: String!): Book
}
type Book {
isbn: String
title: String
author: [String]
publishDate: String
}
`;
const resolvers = {
Query: {
book(parent, args) {
return axios
.get(
`https://openlibrary.org/api/books?bibkeys=ISBN:${
args.isbn
}&jscmd=details&format=json`,
)
.then((res) => transformResponse(res.data[`ISBN:${args.isbn}`].details))
.catch((err) => console.log(err));
},
},
};
const server = new GraphQLServer({ typeDefs, resolvers });
server.start(() => console.log("Server is running on localhost:4000"));Run our yoga server again and use the query:
{
book(isbn: "9780307475312") {
title
author
publishDate
}
}You can find other ISBNs here.

And with that, we've successfully wrapped a basic REST endpoint! From here you can try making the transformResponse function a little more robust and handle multiple returned ISBNs as well as both 10 and 13 digit ISBNs. This is only a server implementation and one piece of a bigger picture, libraries like Apollo Client and Relay make it easier to implement GraphQL calls into your front end application.
Extra Flexibility: Nested REST calls
So far, we've just wrapped a single REST call and returned a single entity to the consumer. It's been nice to specify the data points we're interested in through the query and not send unnecessary data down but we're not really doing anything special yet. To really take advantage of what GraphQL offers, we're going to return data from two distinct endpoints from a single query.
We're going to add some new functionality to our server to search for a movie or show based on a book, returning details if one exists using the OMDb API.
Let's look at our new schema:
type Query {
book(isbn: String!): Book
movie(title: String!): Movie
}
type Book {
isbn: String
title: String
author: [String]
publishDate: String
movie: Movie
}
type Movie {
title: String
year: Int
rated: String
awards: String
}Adding our Movie type is straightforward, exactly the same as when we added our Book type. We updated our Book type and nested our movie type inside, this allows us to query for a movie that's related to a specific book and have it's data attached to the book automatically as it's returned. No extra step needed to stitch the data together.
Our new resolvers may look a little bit complicated but they follow the same pattern:
Query: {
book(parent, args) {
return axios
.get(
`https://openlibrary.org/api/books?bibkeys=ISBN:${
args.isbn
}&jscmd=details&format=json`
)
.then(res =>
transformBookResponse(res.data[`ISBN:${args.isbn}`].details)
)
.catch(err => console.log(err));
},
movie(parent, args) {
return axios
.get(`http://www.omdbapi.com/?t=${args.title}&apikey=[yourApiKeyHere]`)
.then(res => transformMovieResponse(res.data))
.catch(err => console.log(err));
}
},
Book: {
movie: parent => {
return axios
.get(`http://www.omdbapi.com/?t=${parent.title}&apikey=[yourApiKeyHere]`)
.then(res => transformMovieResponse(res.data))
.catch(err => console.log(err));
}
}We've added a movie resolver to our root Query resolver and that corresponds to our root Query schema type, just like the book resolver we had previously. When we query for a Book or Movie these are the resolvers used. In addition to the movie resolver, we add a dedicated Book resolver responsible for handling nested queries and in this case is support for a nested movie query. It functions the same with a key difference.
Now we are using the first argument passed to the resolver function, parent, which will hold the resolved value of the Book we're interested in. This allows us to use the title of the book we've queried for to be used in our movie query to return our movie details.
Note: This is a naive approach and doesn't scale well for multiple nested queries. In production applications the use of a library like dataloader should be used to avoid a lot of headaches. It is outside the scope of this tutorial but I encourage you to read more on it as your use cases become more complex.
You can retrieve your own free API key to run this code by visiting OMDb.
Finally, our updated code should look like:
/index.js
const { GraphQLServer } = require("graphql-yoga");
const axios = require("axios");
const transformBookResponse = (details) => ({
author: details.authors.map((author) => author.name),
isbn: details["isbn_13"],
title: details.title,
publishDate: details.publish_date,
});
const transformMovieResponse = (movie) => ({
title: movie.Title,
year: movie.Year,
rated: movie.Rated,
awards: movie.Awards,
});
const typeDefs = `
type Query {
book(isbn: String!): Book
movie(title: String!): Movie
}
type Book {
isbn: String
title: String
author: [String]
publishDate: String
movie: Movie
}
type Movie {
title: String
year: Int
rated: String
awards: String
}
`;
const resolvers = {
Query: {
book(parent, args) {
return axios
.get(
`https://openlibrary.org/api/books?bibkeys=ISBN:${
args.isbn
}&jscmd=details&format=json`,
)
.then((res) =>
transformBookResponse(res.data[`ISBN:${args.isbn}`].details),
)
.catch((err) => console.log(err));
},
movie(parent, args) {
return axios
.get(`http://www.omdbapi.com/?t=${args.title}&apikey=[yourApiKeyHere]`)
.then((res) => transformMovieResponse(res.data))
.catch((err) => console.log(err));
},
},
Book: {
movie: (parent) => {
return axios
.get(
`http://www.omdbapi.com/?t=${parent.title}&apikey=[yourApiKeyHere]`,
)
.then((res) => transformMovieResponse(res.data))
.catch((err) => console.log(err));
},
},
};
const server = new GraphQLServer({ typeDefs, resolvers });
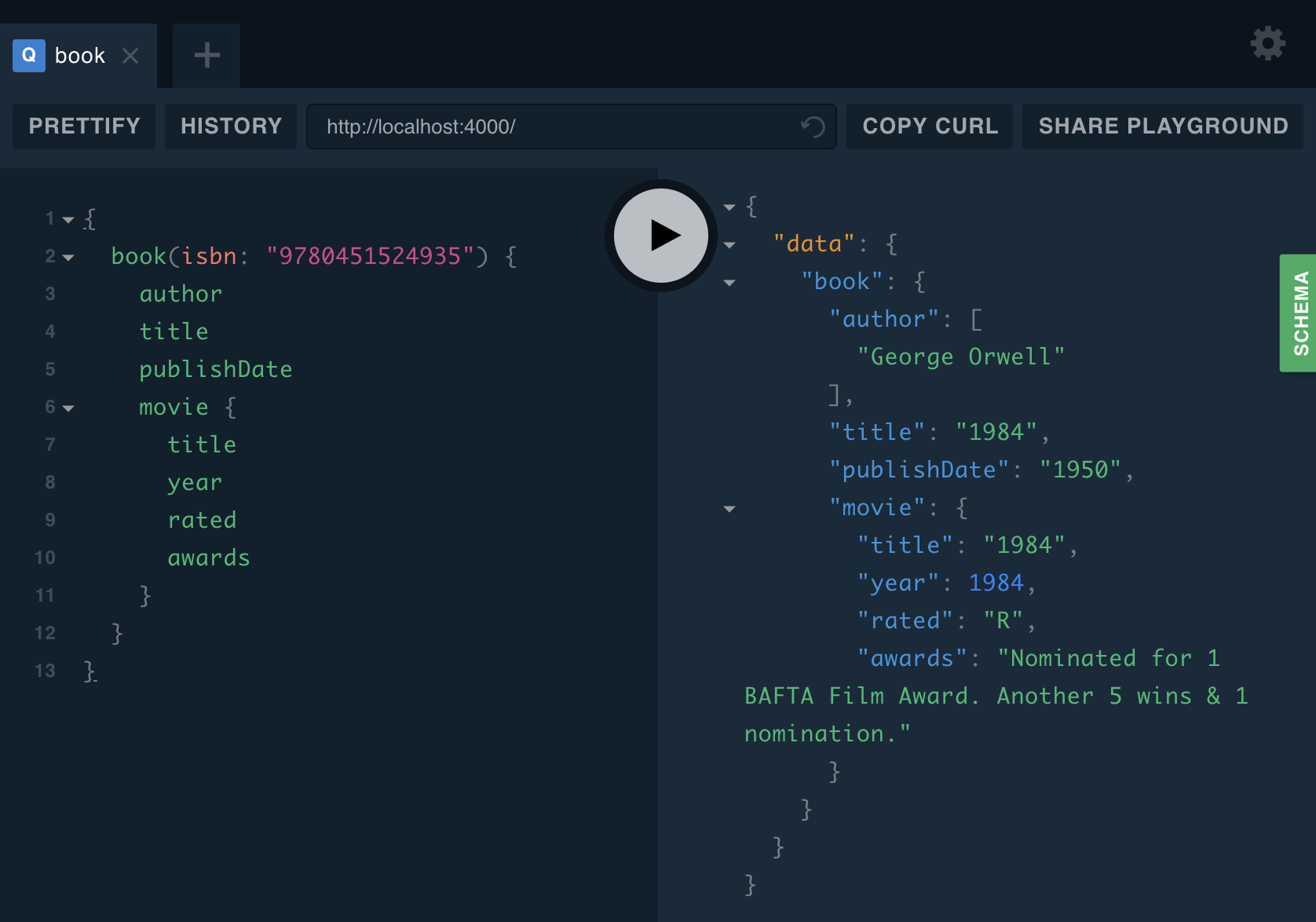
server.start(() => console.log("Server is running on localhost:4000"));As we did before, start up our server and run a query like the one pictured below to view our results.
Query
{
book(isbn: "9780451524935") {
author
title
publishDate
movie {
title
year
rated
awards
}
}
}
Conclusion
We've looked at the GraphQL type language, wrote a schema with custom types, built resolvers to handle queries against our schema, wrapped a REST API, and even handled nested calls. That's pretty impressive! Already, you know how you can reduce the client side traffic of your application and centralize your API.
Some concepts and concerns you'll want to address before adopting GraphQL are authentication, caching, pagination, and security. There are no prescribed approaches to manage these concerns but there are some great libraries and tools that can make life easier.
I hope with your new found understanding of how to build a simple GraphQL server you'll continue to experiment and find ways to integrate GraphQL into your current stack.