


As every organization is different, adopting Cloud Native architectures has unique challenges depending on a variety of factors. In this post, we will not only highlight the benefits of adopting Cloud Native architectures but also clarify misconceptions of what it means to be Cloud Native. We’ll discuss the barriers that Cloud Native can help you overcome to addressing some challenges when adopting Cloud Native and how your organization can get started. On that note, let’s dive in!
Defining Cloud Native Architecture
As you begin learning about Cloud Native Architecture, start with a basic understanding and definition of what it is. But as you learn more about it’s rapidly growing list of capabilities, it becomes harder to succinctly define Cloud Native architecture because any single statement cannot capture the powerful capabilities of this new shift in architecture and operating model. It’s also complicated by the fact that, as a concept, it’s still very new and the path to successfully leveraging it is not just around architecture and design, but also depends on an organization’s maturity in Cloud adoption.
So, then, what is Cloud Native Architecture? In short, it means considering and leveraging the benefits of Cloud computation from the ground up rather than as an afterthought. It’s a shift from building and procuring everything yourself to understanding what services exist within the Cloud, leaving the Cloud vendors to do the heavy lifting while development teams focus on solving unique business problems.
So, is Cloud Native Architecture not just wrapping your monolithic application in a container and hosting it on the Cloud? Although this tends to be an initial step in an organization’s move to Cloud Native (usually termed as a “lift-and-shift” or “Cloud enabled maturity”), it is not Cloud Native. During the lift-and-shift migration, your application has just shifted it’s workload from an on-premise location to the Cloud. Here you are not yet making full use of the managed services that are available to you within the Cloud, with all of it’s auto-scaling, auto-provision, and auto-redundancy capabilities.
An extension of Microservice Architecture principles
By this point, many of us have bought into the benefits of building microservices. We value an architectural mindset that favors loose coupling and decentralization over the traditional centralized monolithic applications. Given that the Cloud in itself is decentralized and distributed, it aligns well with enabling microservices. If you are already designing and following microservice architecture patterns you are on the right step in true Cloud Native Architecture development.
Some of the key building blocks of a loosely coupled, distributed system, are message queues and events. These are all managed services available through Cloud vendors, so you are out of the box set up with the building blocks that enable you to design and architect microservices. With the added benefits that these managed services are built to scale with your needs so you do not need to worry about getting your IT operations team to provision, host and scale these services. Imagine a world where these services were not available to you. Depending on your IT operations’ backlog, this could take weeks or even months to implement, at which point you’ve missed your sprint deadline that was allocated to complete any large spikes. Unfortunately, that means the product owner and engineering team would have to then make the unfortunate decision of putting off any new architectural changes until the next release. Your dev team will either design the architecture to account for loose coupling, or worse, continue creating technical debt by tightly coupling to the monolith because they feel that it is over engineering to create the anti-corruption layer when there is no need for it. Sound familiar?
As depicted below, with Cloud Native you are benefiting from the vendors managing the services you need. This drastically reduces what teams are required to manage, enabling them to make architecturally sound decisions that enable innovation. Go ahead, decouple that new feature.
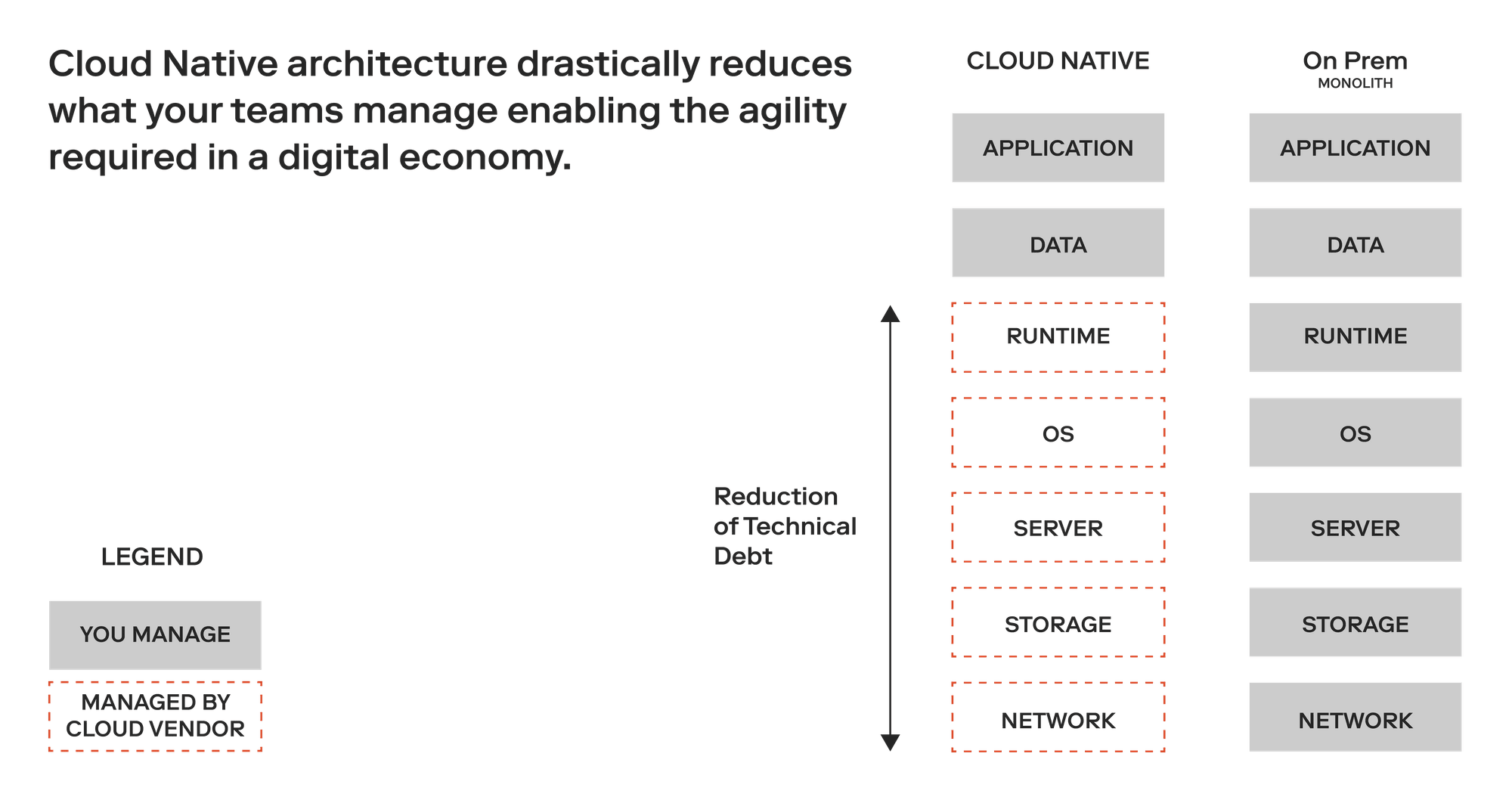
Breaking down traditional barriers for innovation - interested yet?
We’ve already seen how a traditional barriers with IT operations’ ability to procure supporting infrastructure can be removed with the Cloud, and in doing so enables sound innovation. These are the other barriers that are removed when you start building Cloud Native:
- Inter-team dependencies
- Slow release cycles
- Legacy tech stack
Autonomous Cross-Functional Teams - no more inter-team dependencies
When previously dealing with a large enterprise application and a new feature was needed in one module, all modules in the application would need to be deployed as well. Therefore, the product team that owns the change couldn’t release without first planning with other product teams to ensure sufficient QA cycles are available to test all impacted modules, ensuring that nothing is broken. This tight inter-team dependency meant that although the development team could have developed the feature in a couple sprints, the anxiety and sometimes complexity around testing was usually a factor in stifling the team’s ability to innovate.
Cloud native architecture, as an extension of microservices, has created a rise in cross-functional teams that own and operate the service that they are responsible for. Since the services are decoupled, the team is able to respond to changes and in effect, be more agile. They are able to develop, test, deploy and manage their service independently. Releasing changes faster.
Release your ideas faster - no more large release cycles
Large monolithic applications were especially concerning for enterprise clients, who themselves needed time to not only accept new features coming in, but also needed ramp up time to train and document new modules for their user base, go through test cycles of their own to ensure that configurations and functionalities are in check, and procure any new infrastructure requirements if they were deploying on premise. This operational overhead usually meant that clients could only take a couple releases a year.
When you breakdown the monolith in favor of Cloud Native, teams are able to release at the pace of your ideas. Since the entire application doesn’t need to be redeployed and tested, changes can then be released faster. New infrastructure isn’t needed to enable a new feature, so there is no IT operations sign-off required. You’ve removed the cost of doing and can now simply get things done.
Instead of releasing once or twice a year, you can now continuously release as needed. This in turn opens up opportunities to get real user feedback on your new feature. You’re no longer waiting six months to release your idea, you can release as soon as you’re ready and make use of data analytics to monitor how your feature is doing. Learn, make changes, and deploy faster. That’s exciting.
Pick the right tool for the right job - no more legacy tech stacks
When teams own their service, they are also able to pick the technology that is optimal for them and for getting the job done. This would not have been possible before. Aside from infrastructure to host the new technology, there would have been version incompatibility constraints. How many times have you wanted to upgrade to the latest version of a library or framework, but were unable to, because an upgrade meant a loss in functionality for another module X? The product team for X is so overwhelmed with their own backlog that a large scale upgrade isn’t feasible for a couple major releases (we’re talkin’ a year or two). This means the features we wanted in the new library we would have to implement ourselves.
With Cloud Native, we are no longer constrained by tightly coupled dependencies, better yet, by a single technology stack. Since our services are isolated, we are free to choose the right technology for the right job. It means not having to implement underlying capabilities of a particular library or feature within your existing technology stack, and rather focus on implementing business use cases using the right technology stack, the actual effort that provides ROI for your business.
Is architecting for the Cloud any different?
There are design considerations to be mindful of when architecting for the Cloud. The ability for your operations to be transactional and atomic is not possible when an operation spans multiple independent services. Here, you’re most likely going to leverage message queues and events to facilitate communication between your services. This in turn can add latency and concepts of eventual consistency to your design which needs to be accounted for.
An emerging trend in Cloud Native development is the use of serverless computing or Functions as a Service (FaaS). Here you are running a stateless function, that only spins up when needed. You only pay for when the function is actually used, so you can save on cost, since your function is not constantly running as with traditional services. This is a powerful avenue to pursue when developing your distributed application. It does, however, mean that you do need consider another level of latency here. Since your function spins up when it is invoked, you do need to factor this in to your overall design.
What makes CNA especially difficult for Enterprises?
Enterprise level organizations generally have the largest hurdle in adopting Cloud Native architecture. This isn’t from a lack of understanding the benefits, but rather looking at the shift to Cloud as means to finding a solution to all the traditional barriers mentioned earlier. Understandably, this can be a daunting task to solve in parallel with feature enhancements in the current backlog.
There is a tendency to look at Cloud migration from a re-platforming perspective. Making the decision to wipe the slate clean and start from scratch is simply too expensive and usually entails a large endeavor. Sometimes a lot of the core business logic is baked into the code and understanding how your software currently operates will need to be reverse-engineered because those that developed and wrote the business requirements may no longer be with the company. The risk of getting it wrong is far too great.
The other challenge with breaking down the monolith is the ability to start thinking about domains and defining proper bounded contexts. Do we have clear definitions of where the separations lie? This in itself can be a challenge. If developers are used to creating tight coupling and not defining proper isolations, it can take a few iterations to employ best practices.
From an operational perspective there is a lot to consider as well. Giving a team autonomy to own an entire service is hard to swallow, especially if they’re still new to defining proper boundaries. Setting expectations with clients in terms of expecting multiple releases is also a unique challenge that needs to be handled.
From an automation perspective, some legacy code bases are still being packaged and deployed manually. Companies are still looking for ways to get their feet wet with DevOps and formulating a solid CI/CD pipeline. This in itself is something that some companies require ramp-up time to solve.
How do we start?
Large enterprises can move to the Cloud without making large scale changes to their existing code bases. The key is to start small, so that you can learn the nuances of operating in the Cloud. Here some opportunities to consider for new or existing functionalities:
- Stateless logic
- Post-processing functionality
- New isolated functions that are not coupled with current domains
The objective is to find opportunities where you are able to minimize the amount of refactoring that needs to be done in order to start experimenting with your new functionality. These candidates will get your feet wet leveraging anywhere from serverless capabilities to services managed on the Cloud. This will ensure some learning on how your teams need to handle deployment and configuration of your services on the Cloud and how to familiarize themselves with monitoring and toolings necessary to scale your application when in the Cloud.
Also, starting small will ensure that you can begin looking at automating your processes using a CI/CD pipeline to form your initial DevOps practice. Getting a small team interested in experimenting here so that they can take their learnings for future enhancements.
These future enhancements may look like the figure below, where you begin to slowly carve out slices (a domain or proper bounded context) from your monolith and move it to the cloud.
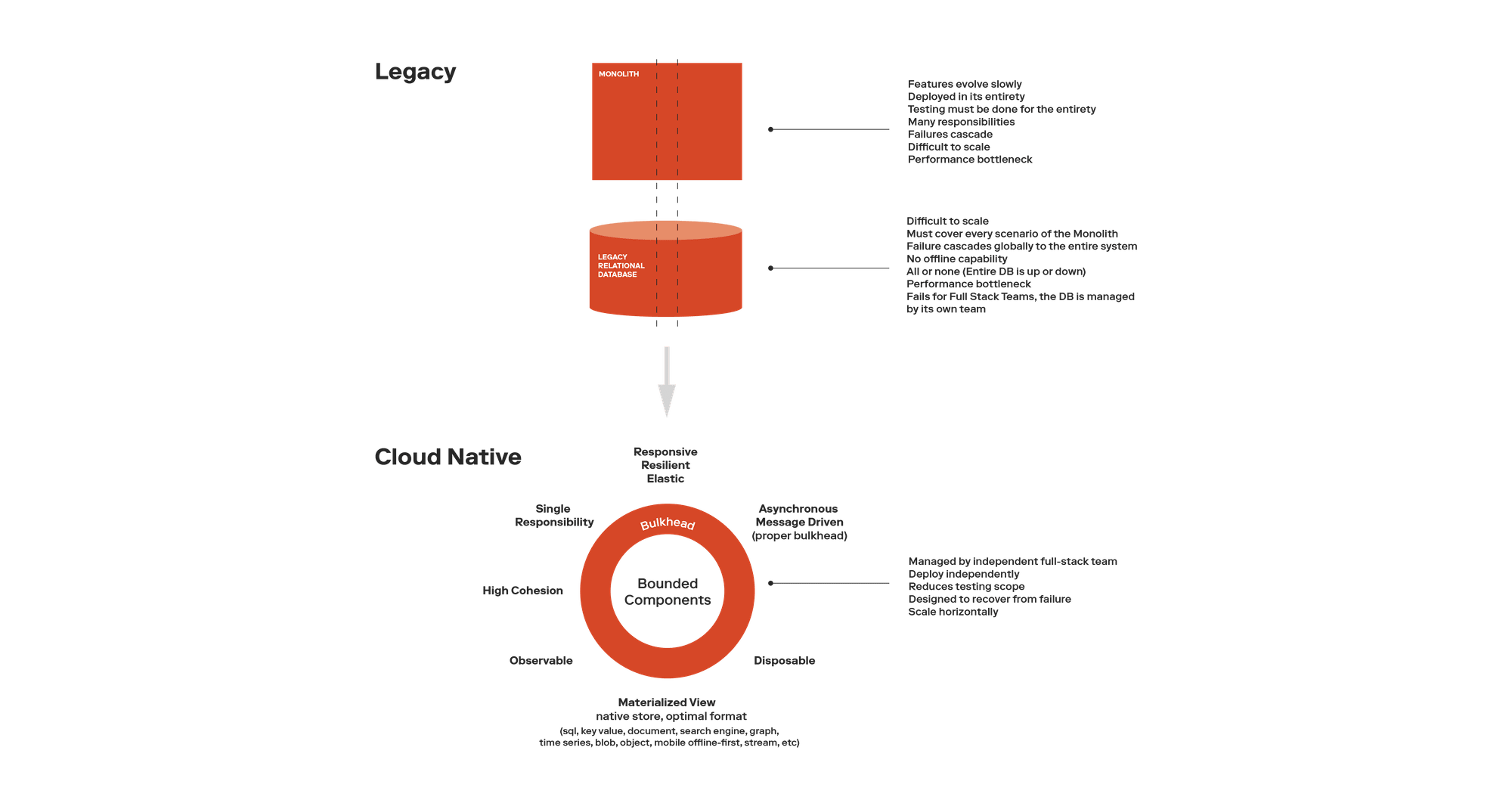
Conclusion
New technology always sounds great, but when it comes time to adopt and integrate it into our own stack, that’s where our unique code bases and operating models pose a challenge not usually documented or widely talked about. By starting small, and taking a segment of work in order to gain familiarity with the Cloud, you will ensure that you can ramp up and learn the inner workings of Cloud Native in this new space. By creating an understanding of how your organization needs to approach Cloud Native and iteratively building up your experiences, you set up your organization to transform your innovation landscape.
Interested in staying up to date on the latest in innovation? Never miss an update by signing up for our newsletter, here.